
Qué es la memoria Long-term
La Long-term Memory en LangGraph se gestiona mediante el concepto de Stores (Almacenes). A diferencia de los Checkpointers (Short-term) que guardan el estado de una conversación específica, los Stores son bases de datos diseñadas para guardar información que debe sobrevivir a múltiples conversaciones y ser accesible en cualquier momento.
Imagina que tu agente es un asistente personal. Si cierras el chat y abres uno nuevo mañana:
- Short-term: Se olvida de lo que hablabais ayer (nuevo hilo).
- Long-term: Todavía recuerda que te llamas "Mike" y tus preferencias, porque están guardadas en su "Store".
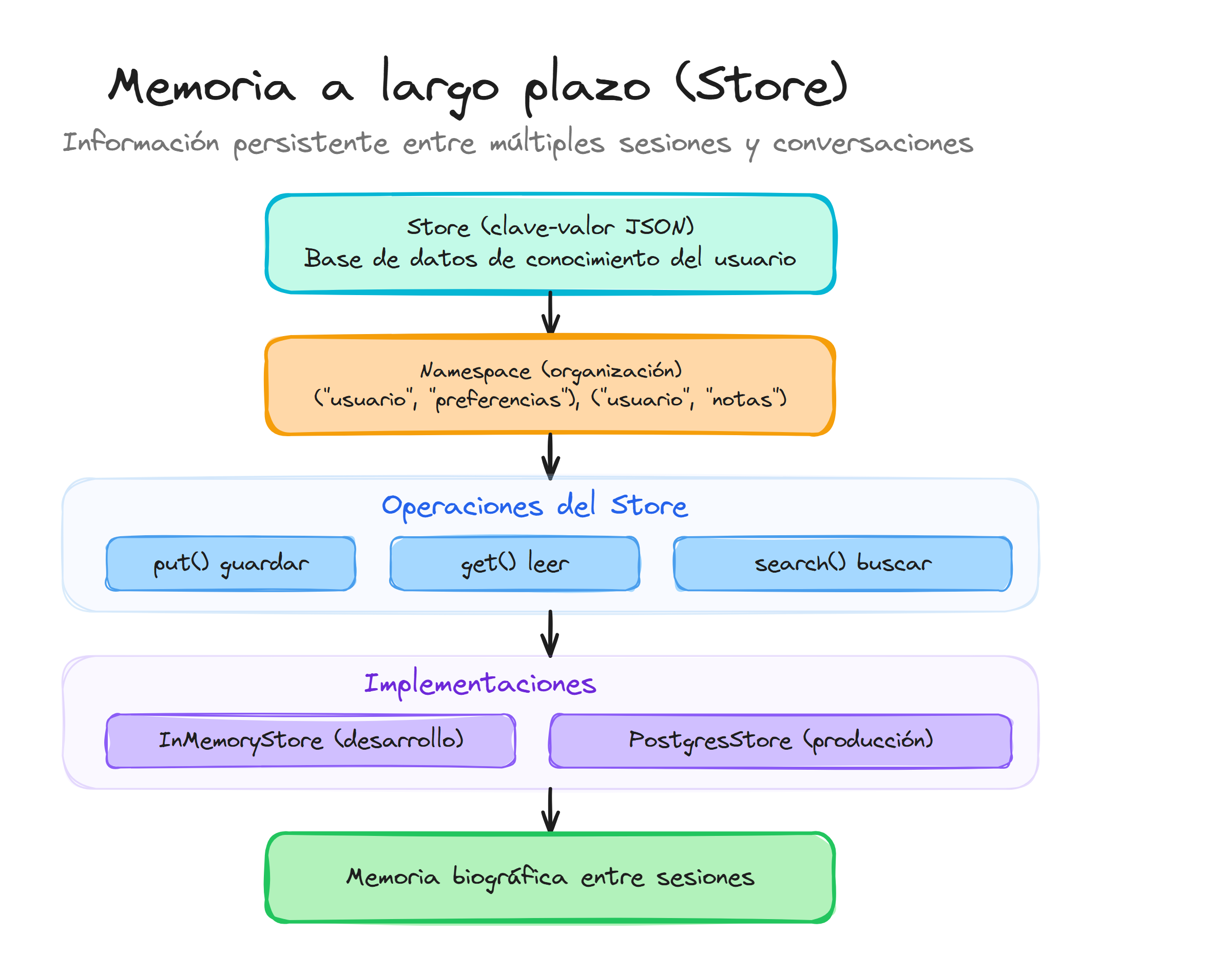
El concepto de Store
Antes de conectarlo al agente, entendamos qué es el Store. Es simplemente una estructura clave-valor donde guardamos documentos JSON organizados por Namespaces (como carpetas).
from langgraph.store.memory import InMemoryStore
# Iniciamos el almacén (volátil, solo en RAM)
store = InMemoryStore()
# Datos del usuario (contexto)
user_id = "user_123"
namespace = ("memoria", user_id) # Carpeta: memoria/user_123
# GUARDAR (PUT): Simulamos que aprendemos algo
store.put(
namespace,
"perfil",
{"nombre": "Mike", "interes": "Python"}
)
# RECUPERAR (GET): Consultamos la memoria manualmente
item = store.get(namespace, "perfil")
print(f"Dato recuperado: {item.value}")
# Salida: {'nombre': 'Mike', 'interes': 'Python'}
2. Integración Básica: inyección de contexto
La forma más sencilla de usar la memoria a largo plazo es recuperarla manualmente y dársela al agente en sus instrucciones. Así el agente "sabe" cosas sin necesidad de herramientas complejas.
Escenario: El usuario inicia un chat nuevo. El agente consulta el Store antes de responder.
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
# 1. Recuperamos la memoria del usuario antes de llamar al agente
recuerdo = store.get(("memoria", "user_123"), "perfil")
contexto_extra = f"Sabes esto del usuario: {recuerdo.value}" if recuerdo else ""
# 2. Creamos un agente simple (sin herramientas de memoria aún)
model = ChatOpenAI(model="gpt-5.4")
agent = create_agent(model=model, tools=[])
# 3. Invocamos al agente inyectando el recuerdo en el mensaje del sistema
response = agent.invoke({
"messages": [
("system", f"Eres un asistente útil. {contexto_extra}"),
("user", "¿Qué debo estudiar hoy?")
]
})
print(response["messages"][-1].content)
# Posible respuesta: "Dado que te interesa Python, te sugiero estudiar decoradores..."
Ventaja: Es simple y fácil de entender. Desventaja: El agente no puede decidir cuándo guardar cosas nuevas ni qué recuperar específicamente; nosotros hacemos el trabajo sucio.
3. Integración Avanzada: Agente Autónomo (Tools)
Para que el agente sea verdaderamente inteligente, debe poder leer y escribir en su memoria por sí mismo usando herramientas.
Aquí surge un reto técnico: ¿Cómo sabe la herramienta quién es el usuario actual? Las herramientas son funciones aisladas. Para solucionar esto, LangGraph introduce el concepto de Context y ToolRuntime.
- Context: Un objeto que viaja con la petición (como el DNI del usuario).
- ToolRuntime: Un objeto especial que da acceso a la herramienta al
storey alcontext.
Ejemplo paso a paso
Primero, definimos qué información de contexto necesitamos (ej. el ID del usuario).
from dataclasses import dataclass
from langchain_core.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
Segundo, creamos herramientas que usen ese contexto para acceder al Store de forma segura.
@tool
def guardar_gusto(gusto: str, runtime: ToolRuntime[Context]) -> str:
"""Guarda un gusto del usuario en su memoria."""
# runtime.context nos dice QUIÉN es el usuario
user_id = runtime.context.user_id
# runtime.store nos da acceso a la base de datos
runtime.store.put(("memoria", user_id), "gustos", {"valor": gusto})
return "Gusto guardado."
@tool
def consultar_gustos(runtime: ToolRuntime[Context]) -> str:
"""Consulta qué le gusta al usuario."""
user_id = runtime.context.user_id
item = runtime.store.get(("memoria", user_id), "gustos")
return item.value["valor"] if item else "No sé nada aún."
Tercero, creamos el agente inyectando el Store y el esquema del Contexto.
agent = create_agent(
model=model,
tools=[guardar_gusto, consultar_gustos],
store=store, # <--- Conectamos el cerebro
context_schema=Context # <--- Explicamos la estructura del contexto
)
# USO: Pasamos el contexto en el invoke
agent.invoke(
{"messages": [("user", "Me encanta la pizza")]},
context=Context(user_id="user_123") # <--- Identificamos al usuario
)
# En otro momento...
response = agent.invoke(
{"messages": [("user", "¿Qué comida me sugieres?")]},
context=Context(user_id="user_123")
)
# El agente usará la herramienta 'consultar_gustos' automáticamente
4. Persistencia Real con PostgresStore
Hasta ahora hemos usado InMemoryStore, que se borra al cerrar el script. Para producción, usamos PostgresStore. La lógica de tu agente y herramientas no cambia nada, solo la inicialización del almacén.
from langgraph.store.postgres import PostgresStore
from psycopg_pool import ConnectionPool
DB_URI = "postgresql://postgres:postgres@localhost:5432/mi_db"
with ConnectionPool(DB_URI) as pool:
# Inicializamos PostgresStore en lugar de InMemoryStore
store = PostgresStore(pool)
store.setup()
# El resto del código de creación del agente es IDÉNTICO
agent = create_agent(
model=model,
tools=[guardar_gusto, consultar_gustos],
store=store,
context_schema=Context
)
- Store: Base de datos clave-valor (JSON) para recuerdos a largo plazo.
- Context: Metadatos (como
user_id) que enviamos en cada petición para saber de quién hablamos. - Manual vs Automático: Puedes inyectar recuerdos en el prompt manualmente o dar herramientas al agente para que gestione su propia memoria.
Store vs Base de datos manual VS RAG
Es común preguntarse por qué usar la abstracción de Store si ya existen herramientas de bases de datos y RAG. Aquí analizamos las diferencias clave:
1. ¿Por qué usar Store vs. SQL manual (SQLAlchemy/ORM)?
Si bien podrías gestionar tu propia tabla de usuarios con SQL puro, el Store ofrece ventajas específicas para agentes:
- Flexibilidad (Schemaless): Un ORM te obliga a definir columnas rígidas (
nombre,edad,email). La memoria de un agente es impredecible (hoy guarda un gusto, mañana un hecho aleatorio). El Store guarda JSONs arbitrarios, permitiendo que el agente evolucione su estructura de memoria sin que tengas que hacer migraciones de base de datos (ALTER TABLE). - Abstracción unificada: Si empiezas con
InMemoryStorepara prototipar y pasas aPostgresStoreoRedisStoreen producción, tu código del agente (store.put/get) no cambia. Si usas SQL directo, estarías acoplado a esa base de datos. - Organización por mamespaces: El Store ya implementa la lógica de organizar datos por
(usuario, hilo, scope), ahorrándote diseñar esa lógica de claves compuestas manualmente.
2. ¿Store con Embeddings vs. RAG tradicional (PGVector)?
Técnicamente ambos pueden usar vectores, pero resuelven problemas distintos:
-
RAG tradicional (InMemoryVectorStore, PGVector, Chroma...):
- Objetivo: Base de conocimiento global. (Ej. "Documentación de Pandas").
- Flujo: Read-heavy (se lee mucho, se escribe poco). Los documentos suelen ser estáticos o cargados en lote.
- Alcance: General (el mismo conocimiento para todos los usuarios).
-
Store con búsqueda semántica (InMemoryStore, PostgresStore, RedisStore...):
- Objetivo: Memoria Biográfica/Episódica. (Ej. "A este usuario le gusta Pandas pero odia NumPy").
- Flujo: Read/Write dinámico. El agente inserta nuevos recuerdos durante la conversación.
- Alcance: Altamente filtrado por usuario. El Store facilita buscar "cosas sobre Python" pero solo dentro del
namespacedel usuario actual. Hacer esto manualmente en RAG requiere gestionar filtros de metadatos en cada consulta y puede ser tedioso.
Usa RAG para que tu bot tenga información global actualizada (manuales, wikis, noticias).
Usa Store para que tu bot sepa sobre el usuario (preferencias, historial).
Diferencias técnicas: Context vs Configurable vs State
Es común confundir estos conceptos al manejar memoria:
1. Configurable (thread_id)
- Uso: Short-term memory.
- Propósito: Le dice al sistema dónde guardar/cargar el snapshot técnico del grafo.
- Naturaleza: Infraestructura pura. El
Checkpointerlo necesita antes de ejecutar nada. - Código:
config={"configurable": {"thread_id": "1"}}.
2. Context (user_id)
- Uso: Long-term memory y Tools.
- Propósito: Inyección de dependencias. Pasa datos estáticos de negocio (IDs, conexiones, secrets) a las herramientas.
- Naturaleza: Datos de negocio inmutables durante la ejecución. Accesible vía
runtime.context. - Código:
context=Context(user_id="u1").
3. AgentState (messages)
- Uso: Lógica conversacional.
- Propósito: Guardar los datos que cambian paso a paso (mensajes, scratchpad).
- Naturaleza: Estado mutable dinámico.
- Código: Se gestiona internamente o se pasa en el input inicial.
Regla de oro:
- ¿Necesitas recuperar el historial del chat? -> Usa Short-term (
thread_id).- ¿Tu herramienta necesita saber quién es el usuario para buscar en la BD? -> Usa Context (
user_id).- ¿Puedes usar ambos a la vez? -> SÍ, y es lo recomendado para apps reales.
¿Es obligatorio usar una clase Context?
Aunque técnicamente podrías pasar parámetros manualmente a las herramientas, usar un Context tipado (con @dataclass o Pydantic) es la práctica recomendada porque:
- Seguridad: Garantiza que el
user_idsiempre llegue a la herramienta (no depende de que el LLM recuerde generarlo). - Limpieza: Oculta parámetros de infraestructura (
user_id,db_conn) de la vista del LLM, permitiéndole concentrarse solo en los argumentos de negocio (dato_a_guardar).
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es la memoria long-term y Stores, usar InMemoryStore para desarrollo, acceder al store desde herramientas mediante ToolRuntime, trabajar con namespaces y keys, guardar y recuperar información persistente, y entender la diferencia entre short-term y long-term memory.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje