Operaciones map, filter y reduce en colecciones
Pipeline de operaciones sobre colecciones
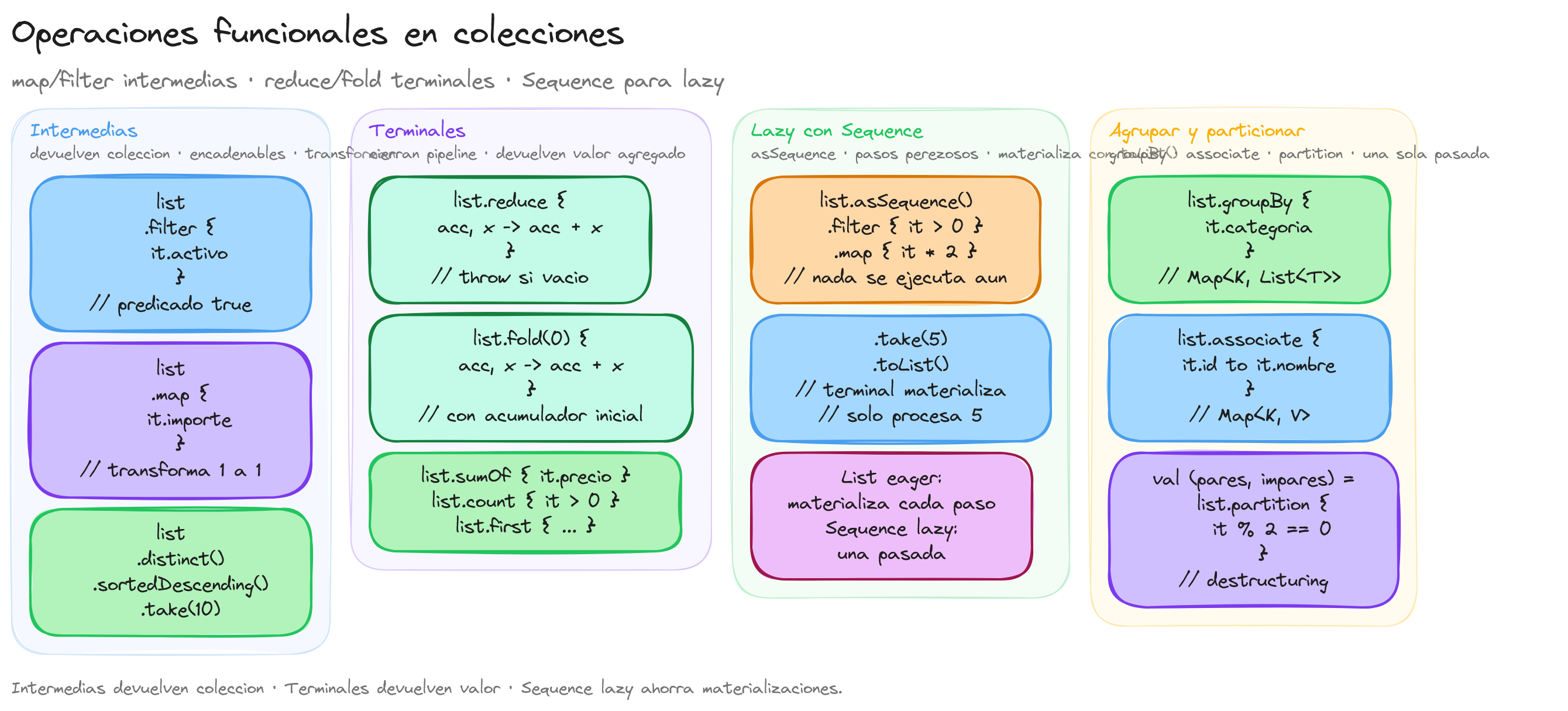
Las operaciones funcionales se categorizan en intermedias (devuelven otra colección) y terminales (cierran el pipeline con un valor agregado). Sobre List se ejecutan eagerly y materializan en cada paso; sobre Sequence se evalúan lazy y solo cuando una terminal las dispara. Conocer la categoría de cada operación previene materializaciones innecesarias.
Una pipeline típica sobre List<Pedido> encadena filter { it.activo } → map { it.importe } → distinct() → sortedDescending() → take(10) y cierra con la terminal reduce { a, b -> a + b } que devuelve un Double. Cada paso intermedio crea una nueva lista en memoria. Si la fuente puede ser grande, conviene transformarla con asSequence(): a partir de ahí filter, map o sorted no calculan nada hasta que una terminal como toList(), first() o count() materialice. Otras terminales habituales además de reduce son fold, sumOf, count, first/last, groupBy y associate, que entregan respectivamente acumulación con valor inicial, suma específica, conteo, primer/último elemento, agrupación en Map<K, List<T>> y proyección a Map<K, V>.
En Kotlin, las funciones map, filter y reduce son operaciones fundamentales para manipular colecciones de manera funcional y declarativa. Estas funciones permiten transformar, filtrar y reducir conjuntos de datos de forma concisa y expresiva.
La función map transforma cada elemento de una colección aplicando una función proporcionada. El resultado es una nueva colección con los elementos transformados:
val numeros = listOf(1, 2, 3, 4, 5)
val cuadrados = numeros.map { numero -> numero * numero }
println(cuadrados) // Imprime: [1, 4, 9, 16, 25]
En este ejemplo, cada número de la lista original se eleva al cuadrado, generando una nueva lista cuadrados con los resultados.
La función filter selecciona los elementos de una colección que cumplen una condición específica, definida por un predicado:
val numeros = listOf(1, 2, 3, 4, 5)
val pares = numeros.filter { it % 2 == 0 }
println(pares) // Imprime: [2, 4]
Aquí, filter extrae los números pares de la lista original, creando una nueva lista pares con dichos elementos.
La función reduce combina los elementos de una colección mediante una operación acumulativa, reduciéndolos a un único valor:
val numeros = listOf(1, 2, 3, 4, 5)
val sumaTotal = numeros.reduce { acumulador, numero -> acumulador + numero }
println(sumaTotal) // Imprime: 15
En este caso, reduce suma los números de la lista, obteniendo el total sumaTotal. Es importante destacar que reduce utiliza el primer elemento como valor inicial del acumulador y puede lanzar una excepción si la colección está vacía.
Para evitar excepciones con colecciones vacías, se puede utilizar reduceOrNull, que devuelve null en lugar de lanzar una excepción:
val numerosVacios = emptyList<Int>()
val suma = numerosVacios.reduceOrNull { acumulador, numero -> acumulador + numero }
println(suma) // Imprime: null
Estas funciones pueden combinarse para realizar operaciones más complejas. Por ejemplo, podemos filtrar y luego mapear los elementos:
val numeros = listOf(1, 2, 3, 4, 5)
val cuadradosDePares = numeros
.filter { it % 2 == 0 }
.map { it * it }
println(cuadradosDePares) // Imprime: [4, 16]
En este ejemplo, primero se filtran los números pares y luego se calcula el cuadrado de cada uno, obteniendo una lista con los cuadrados de los números pares.
Es habitual partir de listas inmutables (listOf, etc.). Las operaciones map, filter y reduce no modifican la colección original: devuelven un resultado nuevo, lo que encaja con un estilo sin efectos secundarios sobre la fuente.
Además de las funciones básicas, Kotlin proporciona variantes como mapIndexed y filterNot. La función mapIndexed incluye el índice de cada elemento durante la transformación:
val letras = listOf("a", "b", "c")
val letrasConIndices = letras.mapIndexed { index, letra -> "$index: $letra" }
println(letrasConIndices) // Imprime: ["0: a", "1: b", "2: c"]
La función filterNot selecciona los elementos que no cumplen el predicado:
val numeros = listOf(1, 2, 3, 4, 5)
val impares = numeros.filterNot { it % 2 == 0 }
println(impares) // Imprime: [1, 3, 5]
Comprender y utilizar eficazmente las funciones map, filter y reduce permite escribir código más legible y conciso, aprovechando las ventajas de la programación funcional en Kotlin.
Uso de fold en colecciones
La función fold en Kotlin es una herramienta fundamental para acumular valores en colecciones. Permite especificar un valor inicial y una operación que se aplicará secuencialmente a cada elemento de la colección, produciendo un único resultado al final del proceso.
La sintaxis básica de fold es la siguiente:
val resultado = coleccion.fold(valorInicial) { acumulador, elemento ->
// operación con acumulador y elemento
}
En este método, el acumulador inicia con el valor proporcionado y se actualiza en cada iteración aplicando la función lambda a cada elemento de la colección. El valor final del acumulador es el resultado devuelto por fold.
Por ejemplo, para calcular la suma de una lista de números enteros:
val numeros = listOf(1, 2, 3, 4, 5)
val suma = numeros.fold(0) { acumulador, numero -> acumulador + numero }
println(suma) // Imprime: 15
Aquí, el valor inicial es 0. En cada paso, se suma el número actual al acumulador, obteniendo al final la suma total de los números de la lista.
Fold también es útil para concatenar cadenas. Supongamos que deseamos unir una lista de palabras en una sola frase:
val palabras = listOf("Kotlin", "es", "un", "lenguaje", "conciso")
val frase = palabras.fold("") { acumulador, palabra ->
if (acumulador.isEmpty()) palabra else "$acumulador $palabra"
}
println(frase) // Imprime: Kotlin es un lenguaje conciso
En este caso, el acumulador comienza como una cadena vacía y se actualiza concatenando cada palabra con un espacio intermedio. De esta forma, se construye una frase completa a partir de la lista de palabras.
Es relevante mencionar que fold realiza un plegado de izquierda a derecha. Existe una variante llamada foldRight, que procesa los elementos de derecha a izquierda:
val numeros = listOf(1, 2, 3)
val resultadoIzquierda = numeros.fold(0) { acumulador, numero -> acumulador - numero }
val resultadoDerecha = numeros.foldRight(0) { numero, acumulador -> numero - acumulador }
println(resultadoIzquierda) // Imprime: -6
println(resultadoDerecha) // Imprime: 2
En foldRight, el orden de los parámetros en la lambda se invierte, y el orden de procesamiento puede afectar al resultado final, especialmente en operaciones no conmutativas como la resta.
Un aspecto importante de fold es su capacidad para manejar colecciones vacías sin generar excepciones. Si la colección está vacía, fold simplemente devuelve el valor inicial, lo que lo hace más seguro en comparación con reduce:
val numerosVacios = emptyList<Int>()
val sumaVacia = numerosVacios.fold(0) { acumulador, numero -> acumulador + numero }
println(sumaVacia) // Imprime: 0
En este ejemplo, incluso con una lista vacía, el resultado es consistente y el programa no falla, lo que aporta robustez al código.
Fold es extremadamente versátil y puede utilizarse para construir estructuras de datos complejas. Por ejemplo, para crear un mapa que cuente la frecuencia de aparición de cada carácter en una lista:
val caracteres = listOf('a', 'b', 'a', 'c', 'b', 'a')
val frecuencia = caracteres.fold(mutableMapOf<Char, Int>()) { acumulador, caracter ->
acumulador[caracter] = acumulador.getOrDefault(caracter, 0) + 1
acumulador
}
println(frecuencia) // Imprime: {a=3, b=2, c=1}
Aquí, el acumulador es un MutableMap que se actualiza en cada iteración para reflejar la frecuencia de cada carácter. Este uso de fold demuestra cómo puede ser empleado para tareas más allá de simples cálculos numéricos.
Al utilizar fold, es aconsejable prestar atención al tipo de estructura de datos que se emplea como acumulador. Dependiendo de la operación, puede ser más eficiente utilizar estructuras mutables o inmutables.
Finalmente, es esencial considerar el rendimiento al trabajar con fold en colecciones grandes. Como procesa cada elemento de la colección, es importante asegurarse de que la operación dentro de la lambda sea lo más eficiente posible para mantener un rendimiento óptimo.
Procesamiento perezoso (lazy) con secuencias en colecciones
En Kotlin, las secuencias (Sequence) ofrecen una manera de procesar colecciones de forma perezosa, lo que significa que los elementos se calculan bajo demanda en lugar de evaluarse inmediatamente. Esto es especialmente útil cuando se trabaja con colecciones grandes o potencialmente infinitas, ya que permite optimizar el rendimiento y reducir el consumo de recursos.
La diferencia principal entre las colecciones y las secuencias radica en su modelo de evaluación. Mientras que las colecciones procesan de forma ansiosa, aplicando cada operación a todos los elementos antes de pasar a la siguiente, las secuencias utilizan un procesamiento perezoso, donde las operaciones se encadenan y se aplican a cada elemento solo cuando es necesario.
Para crear una secuencia a partir de una colección existente, se puede utilizar el método asSequence():
val numeros = listOf(1, 2, 3, 4, 5)
val secuenciaNumeros = numeros.asSequence()
Las operaciones intermedias en una secuencia, como map y filter, son perezosas y no se ejecutan hasta que se invoca una operación terminal, como toList() o sum(). Esto permite combinar múltiples operaciones sin el sobrecoste de crear colecciones intermedias.
Por ejemplo:
val resultado = numeros.asSequence()
.map { it * it }
.filter { it % 2 == 0 }
.toList()
println(resultado) // Imprime: [4, 16]
En este ejemplo, las funciones map y filter se aplican de manera perezosa, y la secuencia solo se evalúa completamente cuando se llama a toList(), generando la lista final con los resultados filtrados y transformados.
El procesamiento perezoso es especialmente útil al buscar elementos que cumplen una condición específica. Por ejemplo, para encontrar el primer número cuadrado par:
val primerParCuadrado = numeros.asSequence()
.map { it * it }
.first { it % 2 == 0 }
println(primerParCuadrado) // Imprime: 4
Aquí, la secuencia procesa los elementos hasta encontrar el primero que satisface la condición, evitando cálculos innecesarios sobre el resto de los elementos.
Es importante tener en cuenta que las secuencias pueden tener un rendimiento inferior en colecciones pequeñas debido al coste adicional de crear objetos de secuencia. Por lo tanto, es recomendable utilizarlas cuando el beneficio del procesamiento perezoso supera dicho coste, como en colecciones grandes o al manejar flujos de datos potencialmente infinitos.
Además de convertir colecciones existentes, Kotlin permite crear secuencias desde cero utilizando funciones como generateSequence y sequence:
val secuenciaInfinita = generateSequence(1) { it + 1 }
val primerosDiez = secuenciaInfinita.take(10).toList()
println(primerosDiez) // Imprime: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
En este caso, generateSequence crea una secuencia que genera números enteros incrementales de forma infinita. Gracias a la función take, podemos obtener solo los primeros diez elementos, evitando así recorrer la secuencia completa.
Las secuencias también son ideales para trabajar con fuentes de datos que se obtienen de manera perezosa, como la lectura de líneas desde un archivo:
File("datos.txt").useLines { lineas ->
val lineasProcesadas = lineas
.filter { it.isNotEmpty() }
.map { it.uppercase() }
.toList()
println(lineasProcesadas)
}
En este ejemplo, useLines proporciona una secuencia de líneas del archivo que se procesa de forma perezosa. Esto mejora la eficiencia al evitar cargar todo el archivo en memoria y permite manejar archivos de gran tamaño con consumo óptimo de recursos.
Sin embargo, se debe tener precaución al utilizar secuencias, ya que ciertas operaciones pueden requerir recorrer la secuencia completa, lo que podría afectar negativamente al rendimiento. Además, las secuencias no se pueden recorrer múltiples veces; si es necesario procesar los datos más de una vez, es preferible convertir la secuencia en una colección mediante toList() o toSet().
En resumen, las secuencias en Kotlin proporcionan una forma efectiva de implementar procesamiento perezoso en colecciones, lo que puede mejorar significativamente el rendimiento y la eficiencia al trabajar con grandes conjuntos de datos o flujos infinitos.
Ejemplos prácticos de transformaciones en colecciones
En esta sección, exploraremos casos prácticos donde las transformaciones en colecciones de Kotlin resultan especialmente útiles. Los ejemplos están diseñados para ilustrar cómo aplicar estas operaciones en situaciones comunes de desarrollo.
Consideremos una lista de objetos de una clase Empleado, donde cada empleado tiene un nombre y un salario:
data class Empleado(val nombre: String, val salario: Double)
val empleados = listOf(
Empleado("Ana", 3000.0),
Empleado("Luis", 2500.0),
Empleado("María", 3200.0),
Empleado("Juan", 2800.0)
)
Supongamos que deseamos obtener una lista con los nombres de los empleados cuyo salario es superior a 2800 euros. Podemos utilizar las funciones filter y map para lograrlo de manera concisa:
val nombresAltosIngresos = empleados
.filter { it.salario > 2800.0 }
.map { it.nombre }
println(nombresAltosIngresos) // Imprime: [Ana, María]
En este ejemplo, filtramos a los empleados por salario y luego mapeamos sus nombres para obtener la lista deseada.
Otro caso práctico es calcular la suma total de los salarios de los empleados. Podemos utilizar la función sumOf para simplificar el cálculo:
val totalSalarios = empleados.sumOf { it.salario }
println(totalSalarios) // Imprime: 11500.0
La función sumOf permite sumar los valores obtenidos al aplicar una expresión a cada elemento de la colección, facilitando la obtención de resultados agregados.
Si deseamos conocer el salario promedio, podemos combinar sumOf con el tamaño de la lista:
val salarioPromedio = empleados.sumOf { it.salario } / empleados.size
println(salarioPromedio) // Imprime: 2875.0
Para casos donde necesitamos agrupar elementos, Kotlin ofrece la función groupBy. Por ejemplo, si clasificamos a los empleados según si su salario es superior o inferior a 3000 euros:
val empleadosPorNivelSalarial = empleados.groupBy {
if (it.salario >= 3000.0) "Altos Ingresos" else "Ingresos Medios"
}
println(empleadosPorNivelSalarial)
// Imprime: {Altos Ingresos=[Empleado(nombre=Ana, salario=3000.0), Empleado(nombre=María, salario=3200.0)], Ingresos Medios=[Empleado(nombre=Luis, salario=2500.0), Empleado(nombre=Juan, salario=2800.0)]}
La función groupBy permite organizar los elementos en un mapa donde la llave es el criterio de agrupación y el valor es una lista de elementos que pertenecen a esa categoría.
También es común necesitar ordenar una colección. Podemos utilizar sortedBy para obtener una lista de empleados ordenados por salario:
val empleadosOrdenados = empleados.sortedBy { it.salario }
empleadosOrdenados.forEach { println("${it.nombre}: ${it.salario}") }
// Imprime:
// Luis: 2500.0
// Juan: 2800.0
// Ana: 3000.0
// María: 3200.0
La función sortedBy devuelve una nueva lista ordenada según el criterio especificado, facilitando la organización de los datos.
Si queremos obtener solo los primeros n elementos tras ordenar, podemos combinar sortedBy con take:
val topDosSalarios = empleados
.sortedByDescending { it.salario }
.take(2)
topDosSalarios.forEach { println("${it.nombre}: ${it.salario}") }
// Imprime:
// María: 3200.0
// Ana: 3000.0
En este caso, ordenamos los empleados de mayor a menor salario y luego tomamos los dos primeros.
Para transformar una lista en un mapa, es posible utilizar la función associateBy. Por ejemplo, crear un mapa donde la clave sea el nombre del empleado y el valor su salario:
val mapaEmpleados = empleados.associateBy { it.nombre }
println(mapaEmpleados)
// Imprime: {Ana=Empleado(nombre=Ana, salario=3000.0), Luis=Empleado(nombre=Luis, salario=2500.0), María=Empleado(nombre=María, salario=3200.0), Juan=Empleado(nombre=Juan, salario=2800.0)}
La función associateBy facilita la creación de mapas a partir de colecciones, usando una función para determinar la clave de cada entrada.
Para emparejar elementos de dos colecciones en el mismo índice, zip es muy útil. Supongamos que tenemos dos listas:
val nombres = listOf("Carlos", "Elena", "Miguel")
val edades = listOf(28, 34, 25)
Podemos combinarlas en una lista de pares utilizando zip:
val personas = nombres.zip(edades)
println(personas)
// Imprime: [(Carlos, 28), (Elena, 34), (Miguel, 25)]
La función zip empareja elementos de dos colecciones, generando una lista de pares.
En ocasiones, es necesario contar el número de elementos que cumplen una condición. La función count es útil para este propósito:
val numeroAltosSalarios = empleados.count { it.salario > 3000.0 }
println(numeroAltosSalarios) // Imprime: 1
Aquí, contamos los empleados con salarios superiores a 3000 euros.
Finalmente, para procesos que requieren aplicar una transformación y aplanar el resultado, flatMap es la elección adecuada. En este ejemplo usamos otro modelo que añade tareas:
data class EmpleadoConTareas(val nombre: String, val salario: Double, val tareas: List<String>)
val empleadosConTareas = listOf(
EmpleadoConTareas("Ana", 3000.0, listOf("Informe mensual", "Reunión equipo")),
EmpleadoConTareas("Luis", 2500.0, listOf("Análisis de datos")),
EmpleadoConTareas("María", 3200.0, listOf("Presentación cliente", "Coordinación")),
EmpleadoConTareas("Juan", 2800.0, listOf("Desarrollo software", "Pruebas"))
)
Para obtener una lista completa de todas las tareas, podemos usar flatMap:
val todasLasTareas = empleadosConTareas.flatMap { it.tareas }
println(todasLasTareas)
// Imprime: [Informe mensual, Reunión equipo, Análisis de datos, Presentación cliente, Coordinación, Desarrollo software, Pruebas]
La función flatMap aplica una transformación a cada elemento y luego fusiona todos los resultados en una única lista.
Estos ejemplos demuestran cómo las operaciones de transformación en colecciones de Kotlin permiten manipular y analizar datos de manera eficiente y concisa, adaptándose a diversas necesidades en el desarrollo de aplicaciones.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Kotlin es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Kotlin
Explora más contenido relacionado con Kotlin y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Comprender y aplicar las funciones
map,filteryreduceen colecciones de Kotlin. - Implementar
foldyreducepara acumulación segura en colecciones. - Explorar el uso de secuencias para procesamiento perezoso.
- Utilizar transformaciones prácticas en colecciones mediante operaciones funcionales.
- Analizar el rendimiento y uso eficiente de colecciones en Kotlin.