Definición y uso de data class
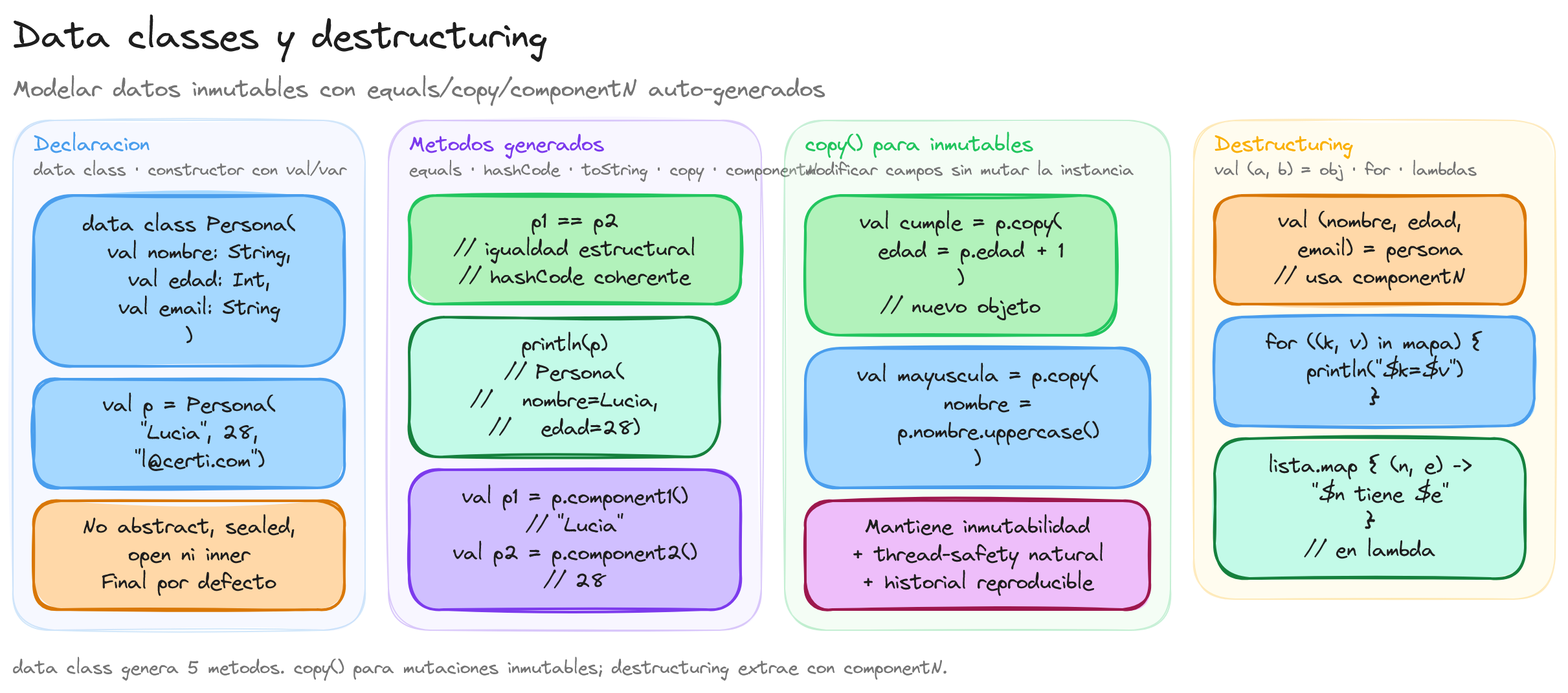
En Kotlin, una data class es una clase diseñada específicamente para representar datos. Estas clases simplifican la creación de objetos cuyo propósito principal es almacenar información sin la necesidad de escribir código adicional para tareas comunes.
Para declarar una data class, se utiliza la palabra clave data antes de la declaración de la clase. Por ejemplo:
data class Persona(val nombre: String, val edad: Int)
En este ejemplo, hemos definido una data class llamada Persona que contiene dos propiedades: nombre y edad. La palabra clave data indica al compilador que esta clase se centrará en mantener datos y que se generarán automáticamente ciertas funciones útiles.
Es necesario que la data class tenga al menos un parámetro en su constructor primario. Además, todos los parámetros del constructor primario deben estar marcados como val o var para que sean propiedades de la clase. Si no se cumplen estas condiciones, el compilador generará un error.
Las data classes no pueden ser declaradas como abstractas, abiertas, selladas ni internas. Esto se debe a que están diseñadas para ser simples contenedores de datos y no para ser extendidas o modificadas en jerarquías de herencia complejas.
El uso de data classes mejora la legibilidad y reduce la cantidad de código necesario al trabajar con objetos que solo contienen datos. Al utilizar data classes, se promueve un estilo de programación más conciso y enfocado en la representación clara de la información.
Data class frente a sealed class
Kotlin ofrece varios tipos de clases especializadas para modelar dominios. Las data class representan un registro concreto de datos; las sealed class (o sealed interface) describen una jerarquía cerrada de variantes conocidas en tiempo de compilación. Elegir bien entre ambas es clave para escribir modelos expresivos.
Con data object estable en el lenguaje, las ramas sin estado de una sealed interface se modelan como data object, lo que garantiza un toString legible sin escribir código adicional.
Métodos generados automáticamente (toString, equals, hashCode, copy)
En las data classes de Kotlin, el compilador genera automáticamente varios métodos que facilitan el manejo de objetos orientados a datos. Estos métodos son toString(), equals(), hashCode() y copy(). Gracias a ellos, se reduce la necesidad de escribir código adicional para tareas comunes, lo que simplifica el desarrollo.
Método toString()
El método toString() proporciona una representación en forma de cadena del objeto, útil para depuración y registro. Por ejemplo:
data class Persona(val nombre: String, val edad: Int)
fun main() {
val persona = Persona("Lucía", 28)
println(persona) // Imprime: Persona(nombre=Lucía, edad=28)
}
Al imprimir el objeto persona, se muestra automáticamente un resumen de sus propiedades, lo que mejora la legibilidad al inspeccionar valores.
Método equals()
El método equals() permite comparar objetos basándose en sus propiedades estructurales. En una data class, dos instancias son iguales si todas sus propiedades son iguales. Por ejemplo:
val persona1 = Persona("Miguel", 35)
val persona2 = Persona("Miguel", 35)
println(persona1 == persona2) // Imprime: true
Aquí, el operador == utiliza el método equals() para determinar que persona1 y persona2 son equivalentes en contenido, aunque sean objetos distintos en memoria.
Método hashCode()
El método hashCode() genera un código hash consistente con equals(), esencial para el correcto funcionamiento en colecciones como conjuntos (Set) o mapas (Map). Por ejemplo:
val conjuntoPersonas = setOf(persona1, persona2)
println(conjuntoPersonas.size) // Imprime: 1
Aunque se añaden dos objetos, el conjunto reconoce que tienen el mismo hashCode() y los trata como un único elemento, evitando duplicados.
El método copy() ofrece una manera sencilla de crear una nueva instancia con los mismos valores que un objeto existente, permitiendo modificar algunas propiedades si es necesario. Esto es especialmente útil para trabajar con objetos inmutables. Por ejemplo:
val persona3 = persona1.copy(edad = 36)
println(persona3) // Imprime: Persona(nombre=Miguel, edad=36)
En este caso, persona3 es una copia de persona1 pero con la propiedad edad actualizada a 36. Esto permite crear variaciones sin alterar el objeto original.
Estos métodos generados automáticamente mejoran la eficiencia y legibilidad al trabajar con data classes, permitiendo enfocarse en la lógica principal sin preocuparse por la implementación de estas funciones esenciales.
Uso de destructuring para extraer datos
En Kotlin, el destructuring permite descomponer un objeto en sus componentes individuales de manera concisa y elegante. Esta funcionalidad es especialmente útil al trabajar con data classes, ya que facilita el acceso directo a sus propiedades sin necesidad de acceder a ellas mediante el objeto.
Cuando se define una data class, el compilador genera automáticamente una serie de funciones llamadas componentN(), donde N es un número que corresponde a la posición de cada propiedad en el constructor primario. Estas funciones son las que hacen posible el destructuring.
Por ejemplo, dada la siguiente data class:
data class Persona(val nombre: String, val edad: Int)
Podemos extraer sus propiedades utilizando una declaración de destructuring:
fun main() {
val persona = Persona("María", 30)
val (nombre, edad) = persona
println("$nombre tiene $edad años")
}
En este código, (nombre, edad) descompone el objeto persona en sus propiedades individuales. Así, nombre obtiene el valor "María" y edad el valor 30. Esto simplifica el acceso a los datos y mejora la legibilidad.
El destructuring también es muy útil en bucles, especialmente al iterar sobre colecciones de objetos. Por ejemplo:
val listaPersonas = listOf(
Persona("Carlos", 25),
Persona("Ana", 28),
Persona("Luis", 22)
)
for ((nombre, edad) in listaPersonas) {
println("$nombre tiene $edad años")
}
Aquí, en cada iteración del bucle for, el objeto Persona se descompone automáticamente en nombre y edad, permitiendo un acceso directo a sus propiedades.
Es posible ignorar algunas propiedades durante el destructuring utilizando el guion bajo _ como marcador de posición. Si solo nos interesa el nombre, podemos hacer lo siguiente:
val persona = Persona("Elena", 35)
val (nombre, _) = persona
println("Nombre: $nombre")
En este caso, estamos descartando la propiedad edad porque no la necesitamos.
El destructuring no se limita únicamente a data classes. Cualquier clase que implemente las funciones componentN() puede aprovechar esta característica. Por ejemplo, en las estructuras de datos como Pair o Triple, es común utilizar el destructuring:
val coordenadas = Pair(10, 20)
val (x, y) = coordenadas
println("Coordenadas X: $x, Y: $y")
En resumen, el uso de destructuring en Kotlin permite escribir código más conciso y legible al simplificar el acceso a los componentes individuales de un objeto. Esta característica mejora la eficiencia del desarrollo y hace que el código sea más fácil de mantener.
Comparación entre data class y clases regulares
En Kotlin, las data class y las clases regulares sirven para propósitos diferentes, aunque a simple vista puedan parecer similares. Es fundamental comprender las diferencias para elegir la opción más adecuada según las necesidades de tu proyecto.
Las data class están diseñadas principalmente para representar datos. Al declarar una clase como data, el compilador genera automáticamente métodos útiles como equals(), hashCode(), toString() y copy(). Esto facilita el trabajo con objetos que solo contienen información y no tienen comportamiento adicional. Por ejemplo:
data class Usuario(val id: Int, val nombre: String)
En este caso, Usuario es una data class que representa un usuario con un id y un nombre. Gracias a la palabra clave data, podemos comparar instancias, copiarlas y obtener una representación legible sin esfuerzo adicional.
Por otro lado, las clases regulares son más flexibles y se utilizan para definir tanto datos como comportamiento. Puedes añadir métodos personalizados, heredar de otras clases y utilizar modificadores como open, abstract o sealed. Por ejemplo:
open class Empleado(val nombre: String, val salario: Double) {
open fun calcularBonificacion() = salario * 0.10
}
Aquí, Empleado es una clase regular que incluye un método para calcular una bonificación. Al ser open, permite la herencia y la personalización en subclases.
Una diferencia clave es que las data class no pueden ser heredadas. No puedes declarar una data class como open ni derivar de una. Esto se debe a que están pensadas para ser clases simples y inmutables que representan datos puros. Las clases regulares, en cambio, sí permiten herencia y pueden ser modificadas según tus necesidades.
Además, en las data class, todas las propiedades del constructor primario deben estar marcadas como val o var, lo que las convierte en propiedades miembros de la clase. En las clases regulares, esto no es obligatorio. Por ejemplo:
class Punto(x: Int, y: Int)
En esta clase regular Punto, x y y son parámetros del constructor pero no son propiedades accesibles desde fuera de la clase a menos que los declares explícitamente.
Otra ventaja de las data class es el soporte para destructuring, que permite extraer fácilmente sus propiedades:
val usuario = Usuario(1, "Laura")
val (id, nombre) = usuario
println("ID: $id, Nombre: $nombre")
Las clases regulares no ofrecen esta funcionalidad de forma predeterminada a menos que implementes manualmente las funciones componentN() correspondientes.
En términos de mutabilidad, aunque puedes definir propiedades var en una data class, es una buena práctica mantenerlas inmutables usando val. Esto refuerza la idea de que las data class representan datos que no cambian, lo cual es beneficioso en contextos concurrentes. En las clases regulares, la mutabilidad es más común y a veces necesaria para el comportamiento de la clase.
Es importante destacar que las data class son ideales para casos como transferencia de objetos entre capas de una aplicación, modelos de datos o respuestas de APIs. Las clases regulares son más adecuadas cuando necesitas encapsular lógica, comportamiento y estados variables.
En cuanto al rendimiento, las data class pueden consumir más recursos debido a los métodos adicionales generados automáticamente. Sin embargo, en la mayoría de los casos, esta diferencia es insignificante y no afecta al rendimiento general de la aplicación.
En resumen, elige una data class cuando necesites una clase que solo contenga datos y benefíciate de los métodos generados automáticamente. Opta por una clase regular cuando requieras más control, herencia o comportamiento personalizado.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Kotlin es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Kotlin
Explora más contenido relacionado con Kotlin y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Comprender la sintaxis y propósito de las data classes en Kotlin.
- Aprender a utilizar métodos generados automáticamente como
toString(),equals(),hashCode()ycopy(). - Implementar técnicas de destructuring para extraer datos de objetos de manera concisa.
- Comparar las diferencias y beneficios entre data classes y clases regulares.
- Aplicar buenas prácticas para mantener la inmutabilidad en data classes.
- Explorar el uso de destructuring en bucles y con colecciones.