Manipulación avanzada
La manipulación avanzada de strings en JavaScript va más allá de las operaciones básicas, permitiéndonos resolver problemas complejos de procesamiento de texto con elegancia y eficiencia. Estas técnicas son esenciales para desarrolladores que necesitan implementar funcionalidades sofisticadas como validación de formatos, análisis de texto o transformaciones complejas.
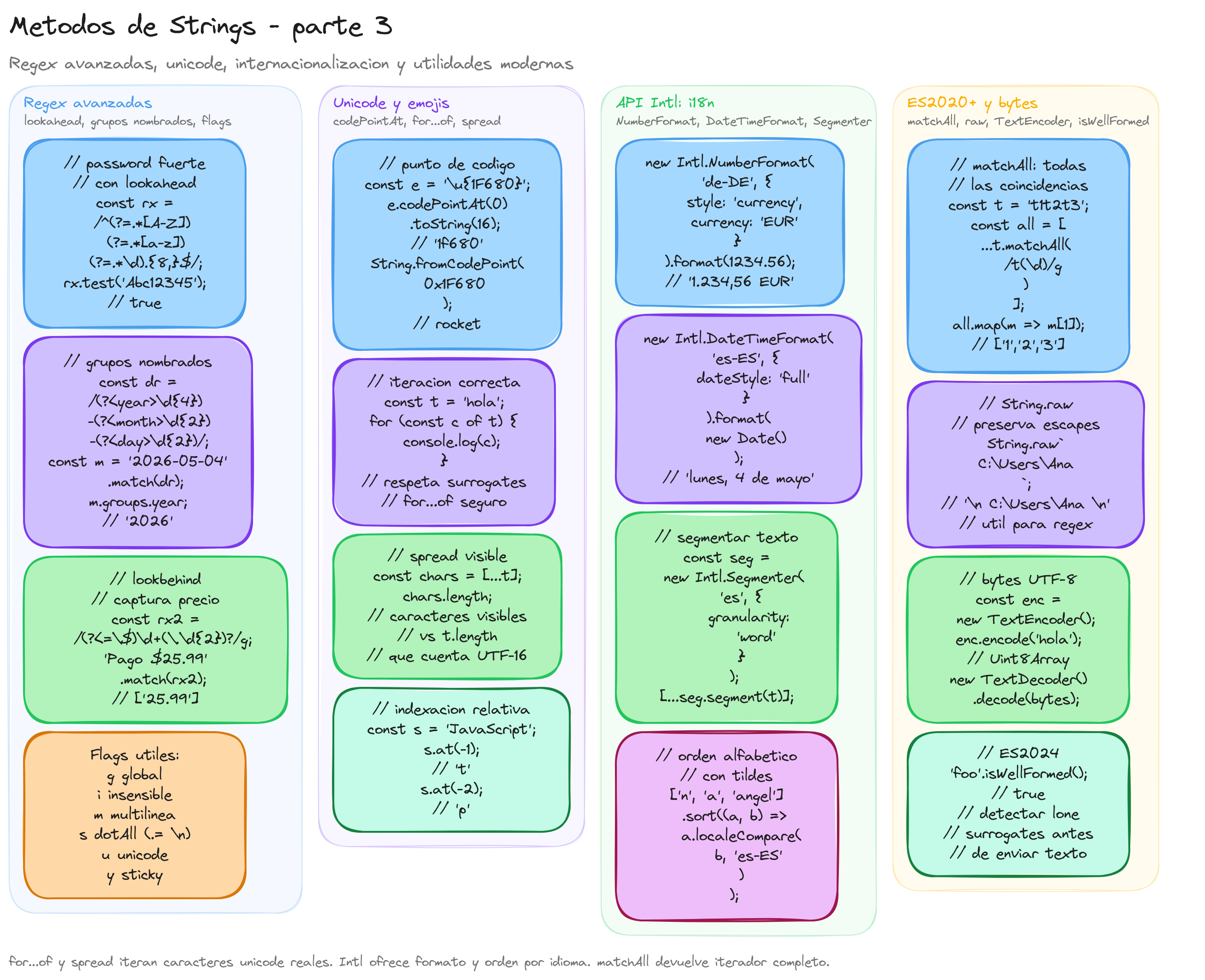
Expresiones regulares avanzadas
Las expresiones regulares son una herramienta útil para manipulación de texto, especialmente cuando necesitamos patrones complejos:
- Lookaheads y lookbehinds
Estas construcciones permiten crear condiciones sin consumir caracteres:
// Contraseña que contenga al menos una letra mayúscula, una minúscula y un número
const strongPassword = /^(?=.*[A-Z])(?=.*[a-z])(?=.*\d).{8,}$/;
console.log(strongPassword.test("Abc12345")); // true
console.log(strongPassword.test("abcdefgh")); // false (sin mayúsculas ni números)
Los lookbehinds (disponibles en navegadores modernos) permiten verificar lo que precede a un patrón:
// Capturar números que estén precedidos por un símbolo $
const priceRegex = /(?<=\$)\d+(\.\d{2})?/g;
const text = "Products: $25.99, €30.50, $15";
console.log(text.match(priceRegex)); // ["25.99", "15"]
- Grupos de captura nombrados
Facilitan el trabajo con partes específicas del patrón:
const dateRegex = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
const match = "2023-11-15".match(dateRegex);
console.log(match.groups.year); // "2023"
console.log(match.groups.month); // "11"
console.log(match.groups.day); // "15"
Esto es particularmente útil para extraer información estructurada:
function parseURL(url) {
const regex = /^(?<protocol>https?):\/\/(?<domain>[^\/]+)(?<path>\/.*)?$/;
const match = url.match(regex);
return match ? match.groups : null;
}
const urlInfo = parseURL("https://developer.mozilla.org/en-US/docs/Web/JavaScript");
console.log(urlInfo);
// { protocol: "https", domain: "developer.mozilla.org", path: "/en-US/docs/Web/JavaScript" }
- Expresiones regulares con flags avanzados
JavaScript soporta varios flags que modifican el comportamiento de las expresiones regulares:
// Flag 's' (dotAll) - permite que el punto coincida con saltos de línea
const multilineText = `First line
Second line`;
console.log(/First.*Second/s.test(multilineText)); // true
console.log(/First.*Second/.test(multilineText)); // false (sin flag 's')
// Flag 'y' (sticky) - busca solo desde la posición lastIndex
const regex = /\d+/y;
const text = "price: 23, quantity: 5";
regex.lastIndex = 7; // Comenzar búsqueda desde la posición 7
console.log(regex.exec(text)[0]); // "23"
Procesamiento de texto Unicode
JavaScript moderno ofrece soporte mejorado para caracteres Unicode, esencial para aplicaciones internacionales:
- Puntos de código y caracteres compuestos
// Obtener el punto de código de un emoji
const emoji = "";
console.log(emoji.codePointAt(0).toString(16)); // "1f680"
// Crear un carácter desde un punto de código
console.log(String.fromCodePoint(0x1f680)); // ""
- Iteración correcta sobre caracteres Unicode
Los emojis y otros caracteres pueden ocupar múltiples posiciones en un string JavaScript:
const text = "🇪🇸";
// Método incorrecto (divide caracteres compuestos)
for (let i = 0; i < text.length; i++) {
console.log(text[i]);
}
// Método correcto usando for...of
for (const char of text) {
console.log(char);
}
// Convertir a array de caracteres Unicode correctamente
console.log([...text]); // ["", "", "🇪🇸"]
console.log(text.length); // 13 (cuenta unidades de código, no caracteres visibles)
console.log([...text].length); // 3 (cuenta caracteres visibles correctamente)
- Normalización para comparaciones
// Comparación de strings con caracteres acentuados
function normalizedCompare(str1, str2) {
return str1.normalize() === str2.normalize();
}
const a = "café"; // 'é' como un solo carácter
const b = "cafe\u0301"; // 'e' seguido del acento combinante
console.log(a === b); // false
console.log(normalizedCompare(a, b)); // true
Manipulación basada en contexto
A veces necesitamos transformar texto basándonos en su contexto o posición:
- Reemplazo condicional
// Censurar palabras inapropiadas pero preservar la primera letra
function censorText(text, badWords) {
return text.replace(new RegExp(`\\b(${badWords.join('|')})\\b`, 'gi'), match => {
return match[0] + '*'.repeat(match.length - 1);
});
}
const message = "That stupid idea is damn ridiculous!";
console.log(censorText(message, ["stupid", "damn"])); // "That s***** idea is d*** ridiculous!"
- Transformación basada en posición
// Convertir snake_case a camelCase
function snakeToCamel(text) {
return text.replace(/_([a-z])/g, (_, char) => char.toUpperCase());
}
console.log(snakeToCamel("user_first_name")); // "userFirstName"
- Manipulación con funciones de orden superior
// Aplicar diferentes transformaciones a partes específicas de un texto
function transformParts(text, pattern, transformer) {
const parts = [];
let lastIndex = 0;
let match;
const regex = new RegExp(pattern, 'g');
while ((match = regex.exec(text)) !== null) {
// Añadir texto sin cambios antes del match
parts.push(text.slice(lastIndex, match.index));
// Añadir texto transformado
parts.push(transformer(match[0]));
lastIndex = match.index + match[0].length;
}
// Añadir el resto del texto
parts.push(text.slice(lastIndex));
return parts.join('');
}
// Ejemplo: Convertir fechas de formato MM/DD/YYYY a DD-MM-YYYY
const text = "Meeting scheduled for 11/15/2023 and follow-up on 12/01/2023";
const result = transformParts(
text,
'\\d{2}/\\d{2}/\\d{4}',
date => {
const [month, day, year] = date.split('/');
return `${day}-${month}-${year}`;
}
);
console.log(result); // "Meeting scheduled for 15-11-2023 and follow-up on 01-12-2023"
Análisis y extracción de información
JavaScript permite implementar analizadores sofisticados para extraer información estructurada:
- Extracción de múltiples ocurrencias
// Extraer todas las URLs de un texto
function extractURLs(text) {
const urlRegex = /https?:\/\/[^\s]+/g;
return text.match(urlRegex) || [];
}
const content = "Check out https://developer.mozilla.org and https://javascript.info for resources.";
console.log(extractURLs(content));
// ["https://developer.mozilla.org", "https://javascript.info"]
- Análisis de texto estructurado
// Analizar un string CSV simple
function parseCSV(text, delimiter = ',') {
const rows = text.trim().split('\n');
return rows.map(row => {
// Manejo básico de campos entre comillas
const fields = [];
let inQuotes = false;
let currentField = '';
for (let i = 0; i < row.length; i++) {
const char = row[i];
if (char === '"') {
inQuotes = !inQuotes;
} else if (char === delimiter && !inQuotes) {
fields.push(currentField);
currentField = '';
} else {
currentField += char;
}
}
fields.push(currentField); // Añadir el último campo
return fields;
});
}
const csvData = `name,age,city
"Smith, John",42,New York
Alice Brown,28,"San Francisco, CA"`;
console.log(parseCSV(csvData));
// [
// ["name", "age", "city"],
// ["Smith, John", "42", "New York"],
// ["Alice Brown", "28", "San Francisco, CA"]
// ]
- Tokenización de texto
// Tokenizar un texto en palabras, respetando puntuación
function tokenize(text) {
// Dividir por espacios pero mantener puntuación como tokens separados
return text.match(/\w+|[^\w\s]/g) || [];
}
const sentence = "Hello, world! This is a test.";
console.log(tokenize(sentence));
// ["Hello", ",", "world", "!", "This", "is", "a", "test", "."]
Manipulación de formato y presentación
- Truncado inteligente de texto
// Truncar texto sin cortar palabras
function smartTruncate(text, maxLength, suffix = '...') {
if (text.length <= maxLength) return text;
// Encontrar el último espacio antes del límite
const truncated = text.slice(0, maxLength);
const lastSpace = truncated.lastIndexOf(' ');
if (lastSpace === -1) return truncated + suffix;
return truncated.slice(0, lastSpace) + suffix;
}
const description = "JavaScript is a programming language that is one of the core technologies of the World Wide Web.";
console.log(smartTruncate(description, 50));
// "JavaScript is a programming language that is one..."
- Formateo de números
// Formatear números con separadores de miles
function formatNumber(num) {
return num.toString().replace(/\B(?=(\d{3})+(?!\d))/g, ",");
}
console.log(formatNumber(1234567.89)); // "1,234,567.89"
// Usando las API nativas de JavaScript
function formatCurrency(amount, currency = 'USD', locale = 'en-US') {
return new Intl.NumberFormat(locale, {
style: 'currency',
currency: currency
}).format(amount);
}
console.log(formatCurrency(1234.56, 'EUR', 'de-DE')); // "1.234,56 €"
console.log(formatCurrency(1234.56)); // "$1,234.56"
Técnicas de rendimiento para manipulación de strings
Cuando trabajamos con strings grandes o realizamos muchas operaciones, el rendimiento se vuelve crucial:
- Concatenación eficiente
// Ineficiente para muchas concatenaciones
function buildStringBad(items) {
let result = '';
for (const item of items) {
result += item + ', '; // Crea un nuevo string en cada iteración
}
return result.slice(0, -2); // Eliminar la última coma y espacio
}
// Más eficiente
function buildStringGood(items) {
return items.join(', '); // Mucho más rápido para arrays grandes
}
// Para construcciones complejas, usar array y join
function buildHTML(data) {
const parts = [];
parts.push('<ul>');
for (const item of data) {
parts.push(` <li id="${item.id}">${item.name}</li>`);
}
parts.push('</ul>');
return parts.join('\n');
}
- Procesamiento por lotes
Para strings extremadamente grandes, procesar por fragmentos:
// Procesar un string muy grande por fragmentos
function countWordsInLargeText(text, batchSize = 10000) {
let wordCount = 0;
let position = 0;
while (position < text.length) {
// Extraer un fragmento
const chunk = text.slice(position, position + batchSize);
// Encontrar límite de palabra completa
let endPos = batchSize;
if (position + batchSize < text.length) {
const nextSpacePos = chunk.lastIndexOf(' ');
if (nextSpacePos !== -1) {
endPos = nextSpacePos + 1;
}
}
// Contar palabras en este fragmento
const words = chunk.slice(0, endPos).match(/\S+/g) || [];
wordCount += words.length;
// Avanzar posición
position += endPos;
}
return wordCount;
}
// Ejemplo con un texto grande
const longText = "Lorem ipsum ".repeat(100000);
console.log(countWordsInLargeText(longText)); // 200000
Strings en JavaScript moderno
JavaScript ha evolucionado significativamente en los últimos años, introduciendo características modernas que mejoran considerablemente el trabajo con strings. Estas nuevas funcionalidades hacen que la manipulación de texto sea más expresiva, concisa y útil, permitiendo resolver problemas complejos con menos código y mayor legibilidad.
Template literals
Los template literals (introducidos en ES6) representan una de las mejoras más significativas en el manejo de strings:
// Sintaxis tradicional
const name = "Alice";
const greeting = "Hello, " + name + "!";
// Template literals
const modernGreeting = `Hello, ${name}!`;
Los template literals ofrecen varias ventajas importantes:
- Interpolación de expresiones
Permiten insertar cualquier expresión JavaScript válida:
const product = {
name: "Laptop",
price: 999,
discount: 0.15
};
const priceTag = `${product.name}: $${product.price} (Save $${(product.price * product.discount).toFixed(2)})`;
console.log(priceTag); // "Laptop: $999 (Save $149.85)"
- Strings multilínea
Facilitan la creación de texto con saltos de línea sin necesidad de caracteres de escape:
const html = `
<div class="card">
<h2>Product Details</h2>
<p>Check out our latest offers</p>
</div>
`;
- Tagged templates
Permiten procesar template literals con funciones personalizadas:
function highlight(strings, ...values) {
return strings.reduce((result, str, i) => {
const value = values[i] || '';
return `${result}${str}${value ? `<span class="highlight">${value}</span>` : ''}`;
}, '');
}
const keyword = "JavaScript";
const text = highlight`Learn ${keyword} in 2023 and boost your career!`;
// "Learn <span class="highlight">JavaScript</span> in 2023 and boost your career!"
Esta técnica es la base de bibliotecas populares como styled-components y graphql-tag.
String.raw
El método String.raw es una función de etiqueta (tag function) que devuelve el texto sin procesar de los template literals, ignorando los caracteres de escape:
// Normalmente, \n crea un salto de línea
console.log(`First line\nSecond line`);
// First line
// Second line
// Con String.raw, los caracteres de escape se preservan literalmente
console.log(String.raw`First line\nSecond line`);
// "First line\nSecond line"
Esto es especialmente útil cuando trabajamos con expresiones regulares o rutas de archivo:
// Sin String.raw, necesitaríamos doble escape
const windowsPath = "C:\\Users\\Admin\\Documents";
// Con String.raw, es más legible
const betterPath = String.raw`C:\Users\Admin\Documents`;
replaceAll() para reemplazos globales
Uno de los métodos más recientes (ES2021) es replaceAll(), que simplifica enormemente los reemplazos múltiples:
const paragraph = "The quick brown fox jumps over the lazy dog. The fox is quick.";
// Forma antigua con expresión regular
const oldWay = paragraph.replace(/fox/g, "wolf");
// Forma moderna
const newWay = paragraph.replaceAll("fox", "wolf");
// "The quick brown wolf jumps over the lazy dog. The wolf is quick."
Métodos de iteración de caracteres
Para trabajar correctamente con caracteres Unicode, especialmente con emojis y otros caracteres que ocupan múltiples unidades de código, JavaScript moderno ofrece mejores herramientas:
const text = "🇪🇸";
// Iteración incorrecta (divide caracteres compuestos)
for (let i = 0; i < text.length; i++) {
console.log(text[i]); // Muestra fragmentos de caracteres
}
// Iteración correcta con for...of
for (const char of text) {
console.log(char); // "", "", "🇪🇸"
}
// Convertir a array de caracteres Unicode correctamente
const chars = [...text];
console.log(chars.length); // 3 (cuenta caracteres visibles correctamente)
El operador spread (...) y el bucle for...of respetan los límites de caracteres Unicode, lo que los hace ideales para trabajar con texto internacional.
Internacionalización con Intl
La API Intl proporciona capacidades avanzadas de internacionalización para strings:
1. Comparación y ordenación sensible al idioma
const names = ["Ángel", "Zoe", "Ñoño", "Adrian"];
// Ordenación que respeta reglas específicas del idioma
names.sort((a, b) => a.localeCompare(b, "es-ES"));
console.log(names); // ["Adrian", "Ángel", "Ñoño", "Zoe"]
2. Formateo de fechas y números
// Formateo de números según la localización
const formatter = new Intl.NumberFormat("de-DE", {
style: "currency",
currency: "EUR"
});
console.log(formatter.format(1234.56)); // "1.234,56 €"
// Formateo de fechas
const date = new Date();
const dateFormatter = new Intl.DateTimeFormat("ja-JP", {
dateStyle: "full",
timeStyle: "long"
});
console.log(dateFormatter.format(date)); // Formato japonés completo
3. Segmentación de texto
La API Intl.Segmenter (relativamente nueva) permite dividir texto en segmentos lingüísticamente significativos:
// Solo disponible en navegadores modernos
if (typeof Intl.Segmenter === "function") {
const segmenter = new Intl.Segmenter("en", { granularity: "word" });
const text = "Hello, world! How are you?";
const segments = [...segmenter.segment(text)];
// Extraer solo palabras
const words = segments
.filter(segment => segment.isWordLike)
.map(segment => segment.segment);
console.log(words); // ["Hello", "world", "How", "are", "you"]
}
Mejoras en expresiones regulares
JavaScript moderno ha introducido características avanzadas para expresiones regulares que mejoran el trabajo con strings:
1. Flag 's' (dotAll)
Permite que el punto coincida con cualquier carácter, incluidos saltos de línea:
const multiline = `First line
Second line`;
// Sin flag 's', el punto no coincide con saltos de línea
console.log(/First.*Second/.test(multiline)); // false
// Con flag 's', el punto coincide con cualquier carácter
console.log(/First.*Second/s.test(multiline)); // true
2. Grupos de captura nombrados
Permiten acceder a grupos capturados por nombre en lugar de por índice:
const regex = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
const match = "2023-11-15".match(regex);
// Acceso moderno por nombre
const { year, month, day } = match.groups;
console.log(`${day}/${month}/${year}`); // "15/11/2023"
3. Método matchAll() (ES2020)
const text = "test1test2test3";
const pattern = /test(\d)/g;
const matches = [...text.matchAll(pattern)];
console.log(matches.map(match => match[1])); // ["1", "2", "3"]
4. Método at() para indexación relativa
const str = "JavaScript";
console.log(str.at(-1)); // "t" (último carácter)
console.log(str.at(-2)); // "p" (penúltimo carácter)
Codificación y decodificación de strings
JavaScript moderno ofrece métodos mejorados para codificar y decodificar strings:
- encodeURIComponent y decodeURIComponent
Para componentes individuales de URL:
const query = "JavaScript strings & encoding";
const encodedQuery = encodeURIComponent(query);
console.log(encodedQuery); // "JavaScript%20strings%20%26%20encoding"
const url = `https://example.com/search?q=${encodedQuery}`;
- TextEncoder y TextDecoder
Para conversiones entre strings y datos binarios:
// Codificar string a bytes (Uint8Array)
const encoder = new TextEncoder();
const text = "Hello, 世界";
const bytes = encoder.encode(text);
console.log(bytes); // Uint8Array(13) [72, 101, 108, 108, 111, 44, 32, 228, 184, 150, 231, 149, 140]
// Decodificar bytes a string
const decoder = new TextDecoder();
const decodedText = decoder.decode(bytes);
console.log(decodedText); // "Hello, 世界"
Estas APIs son especialmente útiles cuando se trabaja con WebSockets, Fetch API o cualquier operación que requiera manipulación de datos binarios.
Strings y estructuras de datos modernas
JavaScript moderno facilita la conversión entre strings y otras estructuras de datos:
Map y Set con strings
// Contar frecuencia de palabras
function wordFrequency(text) {
const words = text.toLowerCase().match(/\w+/g) || [];
const frequency = new Map();
for (const word of words) {
frequency.set(word, (frequency.get(word) || 0) + 1);
}
return frequency;
}
const text = "To be or not to be, that is the question.";
const freq = wordFrequency(text);
// Obtener las 3 palabras más frecuentes
const topWords = [...freq.entries()]
.sort((a, b) => b[1] - a[1])
.slice(0, 3);
console.log(topWords);
// [["to", 2], ["be", 2], ["or", 1]]
Strings y programación funcional
JavaScript moderno permite aplicar técnicas de programación funcional a la manipulación de strings:
// Pipeline de transformaciones de texto
const transformText = text =>
text
.toLowerCase()
.split(' ')
.map(word => word.charAt(0).toUpperCase() + word.slice(1))
.join(' ')
.trim();
console.log(transformText(" javaScript string METHODS "));
// "Javascript String Methods"
JavaScript continúa evolucionando, y con cada nueva versión se introducen características que hacen que el trabajo con strings sea más intuitivo, eficiente y útil. Mantenerse al día con estas características modernas no solo mejora la calidad del código, sino que también aumenta la productividad del desarrollador al proporcionar herramientas más expresivas para manipular texto.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, JavaScript es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de JavaScript
Explora más contenido relacionado con JavaScript y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Comprender la diferencia entre un string y un carácter en JavaScript.
- Utilizar la propiedad
lengthpara conocer el número de caracteres. - Acceder a caracteres individuales usando corchetes o
charAt(). - Buscar substrings con métodos como
indexOf(),includes(), ystartsWith(). - Extraer partes de un string usando
slice(),substring(), ysubstr(). - Comparar strings mediante
charCodeAt()ylocaleCompare(). - Concatenar strings con el operador
+,concat(), y template literals.