HashMap entradas y resolución colisiones
flowchart TB
Put[put k v] --> Hash[hash k]
Hash --> Idx[index buckets length]
Idx --> Bucket[Bucket]
Bucket --> Empty[Empty insertar entry]
Bucket --> Coll[Colisión]
Coll --> List[Lista enlazada]
Coll --> Tree[Tree red black mayor 8]
Put --> Load[load factor 0.75]
Load --> Resize[resize x2 capacity]
Resize --> Reh[Rehash]
La interfaz Map
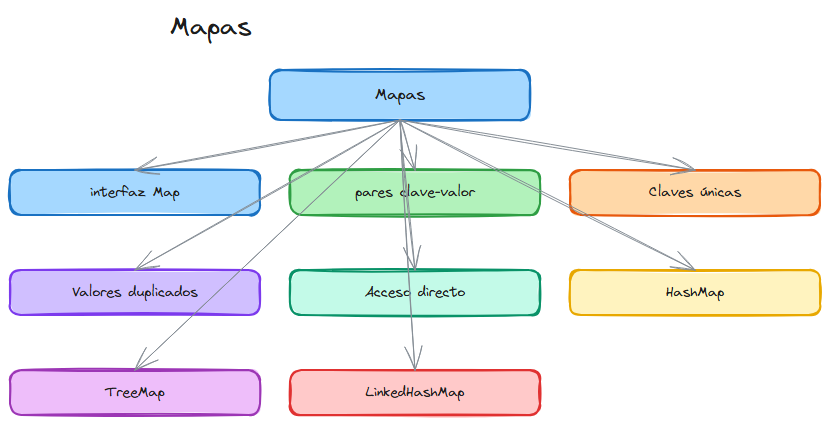
La interfaz Map es uno de los componentes fundamentales del Framework Collections de Java. A diferencia de las colecciones que implementan la interfaz Collection (como List o Set), un Map no almacena elementos individuales, sino que guarda pares clave-valor. Esta estructura es extremadamente útil cuando necesitamos asociar valores con identificadores únicos.
En Java, un Map funciona como un diccionario donde cada elemento tiene una clave única que permite acceder a su valor correspondiente. La interfaz Map está ubicada en el paquete java.útil y define los métodos esenciales para trabajar con este tipo de colecciones.
Características principales de Map
- Pares clave-valor: Cada elemento en un Map consta de una clave y un valor asociado.
- Claves únicas: No puede haber claves duplicadas en un Map.
- Valores duplicados: Los valores sí pueden repetirse para diferentes claves.
- Acceso directo: Permite recuperar, insertar o eliminar elementos mediante su clave.
Métodos básicos de la interfaz Map
La interfaz Map proporciona varios métodos para manipular los pares clave-valor:
// Métodos principales de Map
V put(K key, V value) // Asocia un valor a una clave
V get(Object key) // Obtiene el valor asociado a una clave
V remove(Object key) // Elimina el par clave-valor
boolean containsKey(Object key) // Verifica si existe una clave
boolean containsValue(Object v) // Verifica si existe un valor
int size() // Devuelve el número de pares clave-valor
boolean isEmpty() // Verifica si el mapa está vacío
void clear() // Elimina todos los pares clave-valor
Implementaciones comunes de Map
Java ofrece varias implementaciones de la interfaz Map, cada una con características específicas:
- HashMap: Implementación basada en tablas hash. Ofrece rendimiento constante para operaciones básicas.
- TreeMap: Implementación basada en árboles. Mantiene las claves ordenadas.
- LinkedHashMap: Mantiene el orden de inserción de los elementos.
- Hashtable: Similar a HashMap pero sincronizada (thread-safe).
Ejemplo básico de uso de Map
Veamos un ejemplo sencillo de cómo utilizar un Map en Java:
import java.util.Map;
import java.util.HashMap;
public class EjemploMap {
public static void main(String[] args) {
// Creación de un Map (usando la implementación HashMap)
Map<String, Integer> edades = new HashMap<>();
// Agregar elementos (pares clave-valor)
edades.put("Ana", 25);
edades.put("Carlos", 30);
edades.put("Elena", 28);
// Acceder a un valor mediante su clave
System.out.println("Edad de Carlos: " + edades.get("Carlos"));
// Verificar si existe una clave
if (edades.containsKey("Pedro")) {
System.out.println("Pedro está en el mapa");
} else {
System.out.println("Pedro no está en el mapa");
}
// Modificar un valor existente
edades.put("Ana", 26); // Sobrescribe el valor anterior
System.out.println("Nueva edad de Ana: " + edades.get("Ana"));
// Eliminar un elemento
edades.remove("Elena");
System.out.println("Tamaño del mapa después de eliminar: " + edades.size());
}
}
Recorriendo un Map
Existen varias formas de recorrer un Map en Java:
- 1. Usando el conjunto de claves:
Map<String, Integer> edades = new HashMap<>();
edades.put("Ana", 25);
edades.put("Carlos", 30);
// Recorrer usando el conjunto de claves
for (String nombre : edades.keySet()) {
System.out.println(nombre + " tiene " + edades.get(nombre) + " años");
}
- 2. Usando el conjunto de valores:
// Recorrer solo los valores
for (Integer edad : edades.values()) {
System.out.println("Edad: " + edad);
}
- 3. Usando el conjunto de entradas (pares clave-valor):
// Recorrer pares clave-valor
for (Map.Entry<String, Integer> entrada : edades.entrySet()) {
System.out.println(entrada.getKey() + " tiene " + entrada.getValue() + " años");
}
Métodos adicionales útiles
La interfaz Map proporciona otros métodos útiles para trabajar con mapas:
Map<String, Integer> edades = new HashMap<>();
// Obtener un valor o un valor predeterminado si la clave no existe
int edadAna = edades.getOrDefault("Ana", 0);
// Agregar un valor solo si la clave no existe
edades.putIfAbsent("Carlos", 30);
// Reemplazar un valor solo si la clave existe
edades.replace("Ana", 26);
// Eliminar un par clave-valor solo si coincide con un valor específico
edades.remove("Ana", 26); // Solo elimina si Ana tiene 26 años
Caso práctico: Contador de palabras
Un uso común de los mapas es contar ocurrencias. Veamos cómo implementar un contador de palabras:
import java.util.HashMap;
import java.util.Map;
public class ContadorPalabras {
public static void main(String[] args) {
String texto = "Java es un lenguaje de programación Java es versátil";
String[] palabras = texto.split(" ");
Map<String, Integer> frecuencia = new HashMap<>();
// Contar frecuencia de cada palabra
for (String palabra : palabras) {
// Si la palabra ya existe, incrementa el contador, si no, inicializa a 1
frecuencia.put(palabra, frecuencia.getOrDefault(palabra, 0) + 1);
}
// Mostrar resultados
System.out.println("Frecuencia de palabras:");
for (Map.Entry<String, Integer> entrada : frecuencia.entrySet()) {
System.out.println(entrada.getKey() + ": " + entrada.getValue() + " veces");
}
}
}
Consideraciones al usar Map
- Selección de implementación: Elige la implementación adecuada según tus necesidades (HashMap para rendimiento general, TreeMap para orden, etc.).
- Claves inmutables: Es una buena práctica usar objetos inmutables como claves (String, Integer, etc.).
- Sobrescritura de equals() y hashCode(): Si usas objetos personalizados como claves, asegúrate de sobrescribir correctamente estos métodos.
- Rendimiento: Las operaciones básicas en HashMap tienen un rendimiento de O(1) en promedio, mientras que en TreeMap son O(log n).
Los mapas son estructuras de datos extremadamente versátiles que se utilizan en numerosos escenarios de programación, desde cachés simples hasta complejas estructuras de indexación.
La clase HashMap
La clase HashMap es una de las implementaciones más utilizadas de la interfaz Map en Java. Esta clase proporciona una implementación eficiente basada en tablas hash, lo que permite operaciones de búsqueda, inserción y eliminación con un rendimiento constante en la mayoría de los casos.
HashMap almacena los datos en una estructura interna llamada tabla hash, que organiza los elementos utilizando el código hash de las claves. Esta estructura permite un acceso rápido a los valores sin necesidad de recorrer toda la colección.
Creación de un HashMap
Para crear un HashMap, necesitamos importar la clase desde el paquete java.útil y especificar los tipos de datos para la clave y el valor:
import java.util.HashMap;
// Crear un HashMap con claves de tipo String y valores de tipo Integer
HashMap<String, Integer> puntuaciones = new HashMap<>();
// También podemos especificar la capacidad inicial
HashMap<String, Double> precios = new HashMap<>(20);
// O la capacidad inicial y el factor de carga
HashMap<Integer, String> codigos = new HashMap<>(16, 0.75f);
El factor de carga determina cuándo se redimensionará la tabla hash interna. Un valor más bajo significa menos colisiones pero más uso de memoria, mientras que un valor más alto ahorra memoria pero puede reducir el rendimiento.
Operaciones básicas con HashMap
La clase HashMap implementa todos los métodos de la interfaz Map y añade algunas funcionalidades específicas:
HashMap<String, Integer> estudiantes = new HashMap<>();
// Agregar elementos
estudiantes.put("Juan", 85);
estudiantes.put("María", 92);
estudiantes.put("Carlos", 78);
// Obtener un valor
int puntuacionMaria = estudiantes.get("María"); // Devuelve 92
// Verificar si existe una clave
boolean existeAna = estudiantes.containsKey("Ana"); // Devuelve false
// Eliminar un elemento
estudiantes.remove("Carlos"); // Elimina la entrada de Carlos
// Obtener el tamaño
int numeroEstudiantes = estudiantes.size(); // Devuelve 2 después de eliminar a Carlos
Características específicas de HashMap
A diferencia de otras implementaciones de Map, HashMap tiene algunas características particulares:
- No garantiza orden: El orden de iteración puede cambiar cuando se modifica el mapa.
- Permite una clave null: A diferencia de Hashtable, HashMap permite una clave con valor null.
- Permite valores null: Puede almacenar múltiples valores null.
- No es sincronizado: No es seguro para uso en entornos multihilo sin sincronización externa.
Ejemplo práctico: Gestión de inventario
Veamos un ejemplo práctico donde utilizamos HashMap para gestionar un inventario simple:
import java.util.HashMap;
public class GestionInventario {
public static void main(String[] args) {
// Crear un inventario usando HashMap
HashMap<String, Integer> inventario = new HashMap<>();
// Agregar productos al inventario
inventario.put("Laptop", 5);
inventario.put("Teléfono", 10);
inventario.put("Tablet", 8);
// Mostrar inventario inicial
System.out.println("Inventario inicial: " + inventario);
// Vender 2 laptops
if (inventario.containsKey("Laptop")) {
int cantidadActual = inventario.get("Laptop");
if (cantidadActual >= 2) {
inventario.put("Laptop", cantidadActual - 2);
System.out.println("Venta realizada: 2 laptops");
} else {
System.out.println("Stock insuficiente de laptops");
}
}
// Recibir nuevos teléfonos
int telefonosActuales = inventario.getOrDefault("Teléfono", 0);
inventario.put("Teléfono", telefonosActuales + 5);
// Agregar un nuevo producto
inventario.putIfAbsent("Monitor", 3);
// Mostrar inventario actualizado
System.out.println("Inventario actualizado: " + inventario);
}
}
Rendimiento de HashMap
El rendimiento de HashMap es una de sus principales ventajas:
- Operaciones básicas: Las operaciones
get(),put()yremove()tienen un rendimiento promedio de O(1), lo que significa que el tiempo de ejecución es constante independientemente del tamaño del mapa. - Peor caso: En el peor escenario (muchas colisiones), el rendimiento puede degradarse a O(n), donde n es el número de elementos.
- Redimensionamiento: Cuando el HashMap alcanza su umbral de capacidad (determinado por el factor de carga), se redimensiona automáticamente, lo que puede causar una operación costosa ocasionalmente.
Iteración sobre un HashMap
Existen varias formas de recorrer un HashMap:
HashMap<String, Integer> poblacion = new HashMap<>();
poblacion.put("Madrid", 3223000);
poblacion.put("Barcelona", 1620000);
poblacion.put("Valencia", 791000);
// Método 1: Iterar sobre las claves
for (String ciudad : poblacion.keySet()) {
System.out.println("Ciudad: " + ciudad + ", Población: " + poblacion.get(ciudad));
}
// Método 2: Iterar sobre los valores
for (Integer habitantes : poblacion.values()) {
System.out.println("Población: " + habitantes);
}
// Método 3: Iterar sobre las entradas (más eficiente)
for (HashMap.Entry<String, Integer> entrada : poblacion.entrySet()) {
System.out.println(entrada.getKey() + ": " + entrada.getValue() + " habitantes");
}
El tercer método es generalmente más eficiente cuando necesitamos tanto la clave como el valor, ya que evita búsquedas repetidas en el mapa.
Personalización de claves en HashMap
Cuando usamos objetos personalizados como claves en un HashMap, es crucial sobrescribir correctamente los métodos equals() y hashCode():
import java.util.HashMap;
import java.util.Objects;
class Producto {
private String nombre;
private String categoria;
public Producto(String nombre, String categoria) {
this.nombre = nombre;
this.categoria = categoria;
}
// Getters
public String getNombre() { return nombre; }
public String getCategoria() { return categoria; }
// Sobrescribir equals() y hashCode()
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Producto producto = (Producto) o;
return Objects.equals(nombre, producto.nombre) &&
Objects.equals(categoria, producto.categoria);
}
@Override
public int hashCode() {
return Objects.hash(nombre, categoria);
}
@Override
public String toString() {
return nombre + " (" + categoria + ")";
}
}
public class EjemploHashMapObjetos {
public static void main(String[] args) {
HashMap<Producto, Double> precios = new HashMap<>();
// Crear productos
Producto laptop = new Producto("Laptop XPS", "Electrónica");
Producto telefono = new Producto("Galaxy S21", "Electrónica");
// Agregar al mapa
precios.put(laptop, 1299.99);
precios.put(telefono, 899.99);
// Buscar un producto
Producto buscar = new Producto("Laptop XPS", "Electrónica");
if (precios.containsKey(buscar)) {
System.out.println("Precio de " + buscar + ": " + precios.get(buscar));
}
}
}
Sin la correcta implementación de equals() y hashCode(), el HashMap no podría encontrar correctamente las claves, incluso si representan el mismo objeto conceptualmente.
Diferencias con otras implementaciones de Map
Es importante entender cuándo usar HashMap frente a otras implementaciones:
- HashMap vs Hashtable: Hashtable es sincronizada (thread-safe) pero más lenta. HashMap no es sincronizada pero ofrece mejor rendimiento en entornos de un solo hilo.
- HashMap vs TreeMap: TreeMap mantiene las claves ordenadas, pero sus operaciones son más lentas (O(log n)). HashMap es más rápido pero no mantiene ningún orden.
- HashMap vs LinkedHashMap: LinkedHashMap mantiene el orden de inserción, lo que puede ser útil para ciertas aplicaciones, pero con un pequeño costo de rendimiento adicional.
Uso de HashMap en aplicaciones reales
Los HashMap son extremadamente útiles en muchos escenarios prácticos:
- Cachés: Almacenar resultados de operaciones costosas para acceso rápido.
- Índices: Crear índices para búsquedas rápidas en conjuntos de datos.
- Contadores: Realizar seguimiento de frecuencias o estadísticas.
- Diccionarios: Implementar diccionarios o mapeos de términos.
- Gestión de sesiones: Almacenar información de sesión en aplicaciones web.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en Java
Documentación oficial de Java
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Java es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Java
Explora más contenido relacionado con Java y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la estructura y características de la interfaz Map en Java. Aprender a utilizar los métodos básicos para manipular mapas. Conocer las implementaciones comunes de Map y sus diferencias. Entender el funcionamiento y uso de la clase HashMap. Saber cómo personalizar claves mediante la sobrescritura de equals() y hashCode().
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje