Tipos de datos principales
SQLAlchemy proporciona una amplia gama de tipos de datos que permiten mapear de forma precisa los diferentes tipos de información que necesitamos almacenar en nuestra base de datos. Estos tipos no solo definen cómo se almacenan los datos, sino también cómo se validan y procesan cuando interactuamos con ellos desde Python.
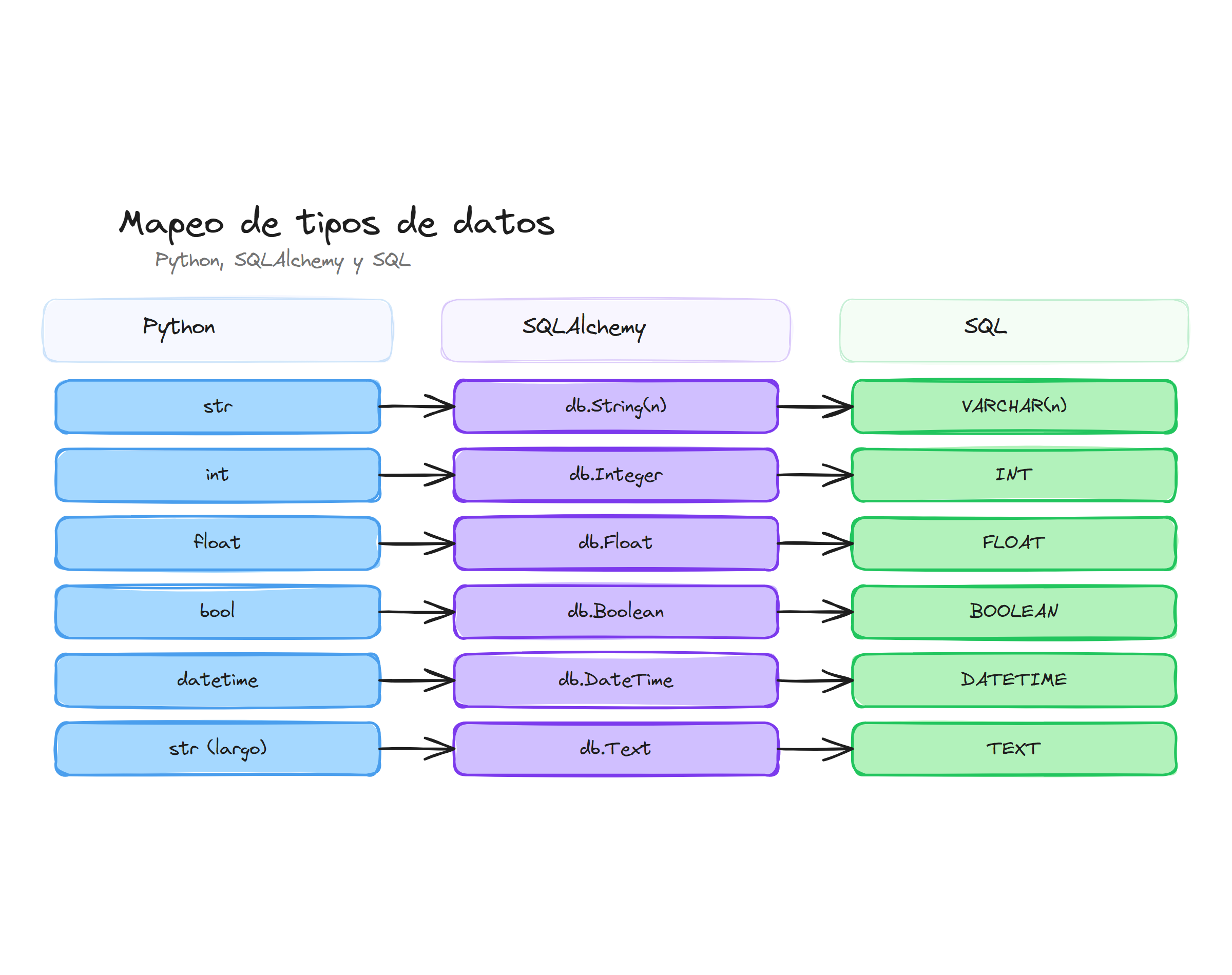
La elección correcta del tipo de dato es fundamental para garantizar la integridad de la información, optimizar el rendimiento de las consultas y aprovechar las características específicas de cada motor de base de datos.
Tipos numéricos
Los tipos numéricos en SQLAlchemy cubren desde números enteros hasta decimales de alta precisión. El tipo más básico es Integer, que almacena números enteros y se mapea automáticamente al tipo correspondiente en la base de datos:
from sqlalchemy import Column, Integer, Float, Numeric
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Producto(db.Model):
id = Column(Integer, primary_key=True)
cantidad = Column(Integer, nullable=False)
precio = Column(Float, nullable=False)
precio_exacto = Column(Numeric(10, 2), nullable=False)
El tipo Float es ideal para valores decimales donde la precisión absoluta no es crítica, como mediciones o cálculos científicos. Sin embargo, para aplicaciones financieras donde cada centavo cuenta, Numeric ofrece precisión decimal exacta especificando el número total de dígitos y los decimales.
Tipos de texto
Los tipos de texto permiten almacenar cadenas de caracteres con diferentes limitaciones de longitud. String requiere especificar una longitud máxima, mientras que Text permite contenido de longitud variable sin límite específico:
from sqlalchemy import String, Text
class Usuario(db.Model):
id = Column(Integer, primary_key=True)
nombre = Column(String(50), nullable=False)
email = Column(String(120), unique=True, nullable=False)
biografia = Column(Text)
codigo_postal = Column(String(10))
La diferencia principal radica en el rendimiento y almacenamiento. String con longitud fija optimiza las consultas y el espacio en disco, mientras que Text ofrece flexibilidad para contenido variable como descripciones o comentarios largos.
Tipos de fecha y tiempo
SQLAlchemy ofrece varios tipos para manejar información temporal con diferentes niveles de precisión. DateTime almacena fecha y hora completas, Date solo la fecha, y Time únicamente la hora:
from sqlalchemy import DateTime, Date, Time
from datetime import datetime, date, time, timezone
class Evento(db.Model):
id = Column(Integer, primary_key=True)
fecha_creacion = Column(DateTime, default=lambda: datetime.now(timezone.utc))
fecha_evento = Column(Date, nullable=False)
hora_inicio = Column(Time, nullable=False)
ultima_actualizacion = Column(DateTime, onupdate=lambda: datetime.now(timezone.utc))
El parámetro default establece un valor automático cuando se crea un registro, mientras que onupdate actualiza el campo cada vez que se modifica el registro. Se usa datetime.now(timezone.utc) en lugar de datetime.utcnow(), que está deprecado desde Python 3.12+. Esto es especialmente útil para campos de auditoría.
Tipos booleanos y de elección
El tipo Boolean almacena valores verdadero/falso y se adapta automáticamente a la representación nativa de cada base de datos. Para campos con opciones limitadas, podemos usar Enum que restringe los valores posibles:
from sqlalchemy import Boolean, Enum
import enum
class EstadoPedido(enum.Enum):
PENDIENTE = "pendiente"
PROCESANDO = "procesando"
ENVIADO = "enviado"
ENTREGADO = "entregado"
class Pedido(db.Model):
id = Column(Integer, primary_key=True)
activo = Column(Boolean, default=True)
estado = Column(Enum(EstadoPedido), default=EstadoPedido.PENDIENTE)
es_urgente = Column(Boolean, default=False)
Los enums proporcionan seguridad de tipos y claridad en el código, evitando errores por valores incorrectos y facilitando el mantenimiento cuando necesitamos agregar nuevos estados.
Tipos binarios y JSON
Para almacenar datos binarios como imágenes o archivos, SQLAlchemy proporciona LargeBinary. El tipo JSON permite almacenar estructuras de datos complejas directamente en la base de datos:
from sqlalchemy import LargeBinary, JSON
class Archivo(db.Model):
id = Column(Integer, primary_key=True)
nombre = Column(String(255), nullable=False)
contenido = Column(LargeBinary)
metadatos = Column(JSON)
configuracion = Column(JSON, default=lambda: {"version": 1, "activo": True})
El tipo JSON es especialmente útil para configuraciones flexibles o datos que no requieren normalización estricta. Los motores de base de datos modernos optimizan las consultas JSON y permiten indexar campos específicos dentro de la estructura.
Configuración de restricciones
Todos los tipos de datos pueden configurarse con restricciones adicionales que garantizan la integridad de los datos. Las más comunes incluyen nullable, unique, default y validaciones personalizadas:
class Cliente(db.Model):
id = Column(Integer, primary_key=True)
nombre = Column(String(100), nullable=False)
email = Column(String(150), unique=True, nullable=False)
edad = Column(Integer, nullable=True)
fecha_registro = Column(DateTime, default=lambda: datetime.now(timezone.utc), nullable=False)
activo = Column(Boolean, default=True, nullable=False)
Estas restricciones se aplican tanto a nivel de base de datos como en la validación de SQLAlchemy, proporcionando múltiples capas de protección contra datos inconsistentes o inválidos.
Definición de modelos básicos
La definición de modelos en Flask con SQLAlchemy sigue un patrón declarativo que permite crear clases Python que representan tablas de base de datos. Cada modelo hereda de db.Model y define la estructura, comportamiento y relaciones de los datos que manejará nuestra aplicación.
Un modelo básico combina la declaración de columnas con métodos que facilitan la manipulación de datos. La estructura fundamental incluye la definición de la tabla, sus campos y las operaciones más comunes que realizaremos sobre los registros.
Estructura básica de un modelo
Todo modelo en SQLAlchemy requiere al menos una clave primaria y sigue una estructura consistente. La clase debe heredar de db.Model y definir explícitamente el nombre de la tabla y sus columnas:
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import Column, Integer, String, DateTime
from datetime import datetime, timezone
db = SQLAlchemy()
class Usuario(db.Model):
__tablename__ = 'usuarios'
id = Column(Integer, primary_key=True)
nombre = Column(String(80), nullable=False)
email = Column(String(120), unique=True, nullable=False)
fecha_creacion = Column(DateTime, default=lambda: datetime.now(timezone.utc))
def __repr__(self):
return f'<Usuario {self.nombre}>'
El atributo __tablename__ específica el nombre de la tabla en la base de datos. Si no se define, SQLAlchemy genera automáticamente un nombre basado en la clase, pero es recomendable especificarlo explícitamente para mayor control.
Métodos de instancia útiles
Los modelos pueden incluir métodos personalizados que encapsulan lógica de negocio y facilitan operaciones comunes. Estos métodos actúan sobre instancias específicas del modelo:
class Producto(db.Model):
__tablename__ = 'productos'
id = Column(Integer, primary_key=True)
nombre = Column(String(100), nullable=False)
precio = Column(Numeric(10, 2), nullable=False)
stock = Column(Integer, default=0)
activo = Column(Boolean, default=True)
def esta_disponible(self):
"""Verifica si el producto está disponible para venta"""
return self.activo and self.stock > 0
def aplicar_descuento(self, porcentaje):
"""Aplica un descuento al precio del producto"""
if 0 <= porcentaje <= 100:
descuento = self.precio * (porcentaje / 100)
return self.precio - descuento
return self.precio
def reducir_stock(self, cantidad):
"""Reduce el stock disponible"""
if self.stock >= cantidad:
self.stock -= cantidad
return True
return False
Estos métodos encapsulan lógica de negocio directamente en el modelo, manteniendo la coherencia y reutilización del código. Cada método opera sobre los datos de la instancia actual y puede modificar sus atributos.
Métodos de clase para consultas
Los métodos de clase proporcionan formas convenientes de realizar consultas específicas sin escribir código repetitivo. Estos métodos se definen con el decorador @classmethod:
class Categoria(db.Model):
__tablename__ = 'categorias'
id = Column(Integer, primary_key=True)
nombre = Column(String(50), unique=True, nullable=False)
descripcion = Column(Text)
activa = Column(Boolean, default=True)
@classmethod
def buscar_por_nombre(cls, nombre):
"""Busca una categoría por su nombre exacto"""
return db.session.execute(
db.select(cls).filter_by(nombre=nombre)
).scalar_one_or_none()
@classmethod
def obtener_activas(cls):
"""Retorna todas las categorías activas"""
return db.session.execute(
db.select(cls).filter_by(activa=True)
).scalars().all()
@classmethod
def crear_categoria(cls, nombre, descripcion=None):
"""Crea una nueva categoría con validación básica"""
if cls.buscar_por_nombre(nombre):
return None # Ya existe
nueva_categoria = cls(nombre=nombre, descripcion=descripcion)
return nueva_categoria
Los métodos de clase actúan sobre la clase completa en lugar de instancias individuales, proporcionando una interfaz limpia para operaciones de consulta y creación que se utilizan frecuentemente.
Validación en modelos
La validación de datos puede implementarse directamente en los modelos usando métodos especiales que SQLAlchemy ejecuta automáticamente durante ciertas operaciones:
from sqlalchemy.orm import validates
class Cliente(db.Model):
__tablename__ = 'clientes'
id = Column(Integer, primary_key=True)
nombre = Column(String(100), nullable=False)
email = Column(String(150), unique=True, nullable=False)
telefono = Column(String(20))
edad = Column(Integer)
@validates('email')
def validar_email(self, key, email):
"""Valida el formato básico del email"""
if '@' not in email or '.' not in email:
raise ValueError("Email debe contener @ y .")
return email.lower()
@validates('edad')
def validar_edad(self, key, edad):
"""Valida que la edad esté en un rango válido"""
if edad is not None and (edad < 0 or edad > 150):
raise ValueError("Edad debe estar entre 0 y 150 años")
return edad
@validates('telefono')
def validar_telefono(self, key, telefono):
"""Limpia y valida el formato del teléfono"""
if telefono:
# Eliminar espacios y caracteres especiales
telefono_limpio = ''.join(filter(str.isdigit, telefono))
if len(telefono_limpio) < 9:
raise ValueError("Teléfono debe tener al menos 9 dígitos")
return telefono_limpio
return telefono
El decorador @validates permite definir validaciones automáticas que se ejecutan cada vez que se asigna un valor al campo correspondiente, garantizando la integridad de los datos antes de llegar a la base de datos.
Propiedades calculadas
Las propiedades calculadas permiten crear campos virtuales que se generan dinámicamente basándose en otros campos del modelo. Estas propiedades no se almacenan en la base de datos:
class Pedido(db.Model):
__tablename__ = 'pedidos'
id = Column(Integer, primary_key=True)
subtotal = Column(Numeric(10, 2), nullable=False)
impuestos = Column(Numeric(10, 2), nullable=False)
descuento = Column(Numeric(10, 2), default=0)
fecha_pedido = Column(DateTime, default=lambda: datetime.now(timezone.utc))
@property
def total(self):
"""Calcula el total del pedido"""
return self.subtotal + self.impuestos - self.descuento
@property
def dias_desde_pedido(self):
"""Calcula los días transcurridos desde el pedido"""
return (datetime.now(timezone.utc) - self.fecha_pedido).days
@property
def resumen(self):
"""Genera un resumen del pedido"""
return {
'id': self.id,
'subtotal': float(self.subtotal),
'total': float(self.total),
'dias': self.dias_desde_pedido
}
Las propiedades se comportan como atributos normales pero ejecutan código cada vez que se accede a ellas, permitiendo cálculos dinámicos y presentación de datos procesados sin almacenamiento adicional.
Serialización de datos
Para facilitar la conversión a JSON y el intercambio de datos con APIs, los modelos pueden incluir métodos de serialización que transforman los objetos Python en diccionarios:
class Articulo(db.Model):
__tablename__ = 'articulos'
id = Column(Integer, primary_key=True)
titulo = Column(String(200), nullable=False)
contenido = Column(Text)
fecha_publicacion = Column(DateTime, default=lambda: datetime.now(timezone.utc))
publicado = Column(Boolean, default=False)
def to_dict(self, incluir_contenido=True):
"""Convierte el artículo a diccionario"""
data = {
'id': self.id,
'titulo': self.titulo,
'fecha_publicacion': self.fecha_publicacion.isoformat(),
'publicado': self.publicado
}
if incluir_contenido:
data['contenido'] = self.contenido
return data
def to_json(self, incluir_contenido=True):
"""Convierte el artículo a JSON"""
import json
return json.dumps(self.to_dict(incluir_contenido))
@classmethod
def from_dict(cls, data):
"""Crea un artículo desde un diccionario"""
return cls(
titulo=data.get('titulo'),
contenido=data.get('contenido'),
publicado=data.get('publicado', False)
)
Los métodos de serialización proporcionan control granular sobre qué datos se exponen y cómo se formatean, facilitando la integración con APIs REST y la transferencia de datos entre diferentes partes de la aplicación.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en Flask
Documentación oficial de Flask
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Flask es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Flask
Explora más contenido relacionado con Flask y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender los tipos de datos principales en SQLAlchemy y su uso adecuado. Aprender a definir modelos básicos en Flask con SQLAlchemy. Implementar métodos de instancia y de clase para encapsular lógica y consultas. Aplicar validaciones automáticas en los modelos para garantizar la integridad de datos. Utilizar propiedades calculadas y métodos de serialización para manipular y exponer datos.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje