Tipos de salidas de modelos de IA
Los modelos de inteligencia artificial pueden generar diversos tipos de salidas según la tarea y el contexto. Comprender estos tipos es fundamental para integrarlos eficazmente en aplicaciones prácticas. Principalmente, las salidas de los modelos de IA se dividen en dos categorías: salidas no estructuradas y salidas estructuradas.
Las salidas no estructuradas son aquellas que no siguen un formato predeterminado. Un ejemplo típico es el texto libre generado en lenguaje natural, como respuestas a preguntas abiertas o generación de historias. Estas salidas son ricas en contenido pero pueden ser difíciles de procesar automáticamente debido a su naturaleza impredecible y sin estructura definida.
Por otro lado, las salidas estructuradas siguen un formato específico que facilita su procesamiento y análisis por sistemas informáticos. Formatos como JSON o XML son ampliamente utilizados para representar datos estructurados. Al obtener salidas en estos formatos, es posible integrarlas directamente en aplicaciones o bases de datos, mejorando la eficiencia y reduciendo la necesidad de procesamiento adicional.

Los tipos de salida que ofrece la API chat de OpenAI son:
- Text: Devuelve respuestas en formato de texto plano. Ideal para interacción directa con el usuario o aplicaciones que no requieren procesamiento estructurado.
- JSON object: Respuestas estructuradas como un objeto JSON, útil para integraciones programáticas donde los datos deben ser procesados o manipulados fácilmente. Se trata de la primera versión de Structured Outputs que ofrece Open AI, también conocida como JSON Mode.
- JSON schema: Genera respuestas ajustadas a un esquema JSON predefinido, asegurando que los datos sigan una estructura y validación específicas para aplicaciones más avanzadas y estrictas. Se trata de la opción avanzada de Structured Outputs que ofrece Open AI con validación de esquema y es la opción más recomendable.
La elección entre salidas estructuradas y no estructuradas depende de los objetivos de la aplicación. Para tareas que requieren análisis automatizado o integración con otros sistemas, las salidas estructuradas son más adecuadas. Por ejemplo, en una aplicación que extrae información específica de un texto, es beneficioso que el modelo de IA devuelva los datos en un formato estructurado como un objeto JSON con campos claramente definidos.
Implementar salidas estructuradas en modelos de IA requiere diseñar las instrucciones o prompts que se le proporcionan al modelo. Es esencial orientar al modelo para que genere la información en el formato deseado, incluyendo detalles sobre la estructura y los campos necesarios. Además, se pueden utilizar herramientas y técnicas avanzadas para validar y garantizar que la salida cumple con un esquema predefinido.
Un beneficio clave de las salidas estructuradas es la mejora en la interoperabilidad entre sistemas. Al estandarizar el formato de salida, diferentes componentes de software pueden comunicarse y compartir datos de manera más eficiente. Esto es especialmente relevante en entornos donde múltiples servicios o microservicios interactúan entre sí, ya que facilita la coordinación y reduce errores causados por discrepancias en los formatos de datos.
Antes de trabajar con salidas estructuradas, conviene conocer cómo obtener salidas en formato texto:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Eres un asistente experto en la biblioteca 'openai' de Python."},
{
"role": "user",
"content": "Explica los principales métodos de la API de 'openai' de Python."
}
]
)
response = completion.choices[0].message
response
La salida obtenida es un objeto ChatCompletionMessage que contiene dentro un texto con la respuesta, pero no está estructurado en JSON.
Qué es JSON y cómo se puede usar en Python con la biblioteca json
JSON (JavaScript Object Notation) es un formato ligero de intercambio de datos que es fácil de leer y escribir tanto para humanos como para máquinas. Se basa en una notación de objetos simple y utiliza pares clave-valor para representar datos estructurados. JSON es independiente del lenguaje de programación y se ha convertido en un estándar para la comunicación entre aplicaciones web y servicios.
La estructura de JSON se compone de objetos y arrays. Un objeto es una colección desordenada de pares clave-valor, encerrados entre llaves {}. Un array es una lista ordenada de valores, encerrados entre corchetes []. Los valores pueden ser cadenas, números, objetos, arrays, booleanos (true o false) o null. Esta flexibilidad permite representar datos complejos de manera sencilla y eficiente.
En Python, la biblioteca estándar json proporciona funciones para trabajar con datos en formato JSON. Esta biblioteca permite convertir objetos de Python a cadenas JSON (serialización) y viceversa (deserialización). A continuación, se presentan las funciones principales de la biblioteca json y cómo utilizarlas.
Para convertir un objeto de Python a una cadena JSON, se utiliza la función json.dumps(). Por ejemplo:
import json
datos = {
'nombre': 'Ana',
'edad': 28,
'ciudad': 'Madrid',
'intereses': ['programación', 'música', 'viajes']
}
json_str = json.dumps(datos)
print(json_str)
En este ejemplo, el diccionario datos se convierte en una cadena JSON. La función json.dumps() acepta parámetros opcionales como indent para mejorar la legibilidad:
json_str = json.dumps(datos, indent=4)
print(json_str)
Para escribir un objeto de Python directamente en un archivo en formato JSON, se utiliza json.dump():
with open('datos.json', 'w') as archivo_json:
json.dump(datos, archivo_json, indent=4)
La función json.dump() escribe el objeto datos en el archivo datos.json con una indentación de 4 espacios, lo que facilita la lectura del archivo generado.
Para leer datos desde una cadena JSON y convertirlos en un objeto de Python, se utiliza json.loads():
json_str = '{"nombre": "Carlos", "edad": 35, "ciudad": "Barcelona"}'
datos = json.loads(json_str)
print(datos)
Aquí, la cadena JSON json_str se convierte en un diccionario de Python. La función json.loads() analiza la cadena y construye el objeto correspondiente.
Para leer datos desde un archivo JSON y convertirlos en un objeto de Python, se utiliza json.load():
with open('datos.json', 'r') as archivo_json:
datos = json.load(archivo_json)
print(datos)
La función json.load() lee el contenido del archivo datos.json y lo convierte en un objeto de Python, como un diccionario o una lista, dependiendo de la estructura del JSON.
Es importante tener en cuenta que la biblioteca json trabaja con tipos de datos básicos. Algunos tipos de datos de Python, como las tuplas o los objetos personalizados, no se pueden convertir directamente a JSON. Sin embargo, es posible extender la serialización implementando un serializador personalizado.
Por ejemplo, si se necesita serializar un objeto que contiene una fecha, se puede crear un codificador personalizado:
from datetime import datetime
class MiEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.isoformat()
return super().default(obj)
datos = {
'evento': 'Conferencia',
'fecha': datetime.now()
}
json_str = json.dumps(datos, cls=MiEncoder)
print(json_str)
En este caso, MiEncoder hereda de json.JSONEncoder y redefine el método default para manejar objetos de tipo datetime.
La biblioteca json en Python es esencial para trabajar con datos estructurados y permite integrar aplicaciones de manera eficiente. Al utilizar JSON, se facilita la comunicación entre diferentes sistemas y lenguajes, aprovechando un formato estándar y ampliamente soportado.
Diferencias entre JSON Object y JSON Schema
En la API de Azure OpenAI Service cuando se usa un modelo con soporte para salidas estructuradas se puede ver que ofrece el modo json object y json schema.
El modo JSON object se refiere al formato en el que las respuestas generadas se estructuran como objetos JSON básicos. El modelo interpreta el contexto y genera un objeto JSON basado en el prompt o la instrucción del usuario, pero sin validación estricta. Esto depende únicamente de las instrucciones proporcionadas en el prompt, y no hay garantía de validación contra un esquema definido.
El modo JSON Schema permite a los desarrolladores definir un esquema JSON explícito como parte de la solicitud. Este esquema describe la estructura, los tipos de datos y las validaciones de las respuestas esperadas. Esto asegura que el modelo genere salidas que cumplan estrictamente con el esquema especificado. La respuesta del modelo se ajustará automáticamente al esquema definido, reduciendo errores y garantizando que la estructura sea válida.
JSON Schema es, por tanto, un formato para describir y validar la estructura de datos en JSON. Actúa como un contrato que define cómo debe ser la estructura de un JSON Object, especificando los tipos de datos, propiedades requeridas, valores permitidos y otras restricciones. JSON Schema es esencial para garantizar la integridad y validez de los datos que se reciben o se envían, especialmente en aplicaciones que dependen de formatos de datos estrictos.
Al seleccionar el modo json schema en Azure nos abre un popup con un ejemplo de cómo es un schema:

Diferencias clave entre JSON Object y JSON Schema:
- Propósito:
- JSON Object: es la representación de datos en sí misma. Contiene la información que se quiere transmitir o almacenar.
- JSON Schema: es una descripción de cómo debe ser la estructura de un JSON Object. Específica reglas y restricciones para validar objetos JSON.
- Estructura:
- JSON Object: se enfoca en los valores reales de datos, organizados en pares clave-valor.
- JSON Schema: utiliza palabras clave específicas definidas por la especificación de JSON Schema (como
"type","properties","required") para describir la estructura y restricciones.
- Uso:
- JSON Object: se usa para transportar y almacenar datos. Es el formato común en APIs, configuraciones y persistencia de datos.
- JSON Schema: se emplea para validar objetos JSON, asegurándose de que cumplen con un formato específico antes de procesarlos o almacenarlos.
- Validación:
- JSON Object: por sí solo, no provee mecanismos de validación. Es simplemente una estructura de datos.
- JSON Schema: se utiliza junto con validadores que comprueban si un JSON Object cumple con el esquema definido, facilitando el manejo de errores y la integridad de los datos.
Al trabajar con APIs y servicios que intercambian datos en formato JSON, es esencial garantizar que los datos recibidos y enviados tienen la estructura esperada. JSON Schema proporciona los medios para definir claramente esta estructura y automatizar su validación. Esto es especialmente relevante en aplicaciones escalables y colaborativas, donde múltiples desarrolladores y sistemas interactúan.
Además, al usar JSON Schema, se pueden generar automáticamente documentación y código para clientes y servidores, mejorando la eficiencia en el desarrollo y mantenimiento de aplicaciones. También facilita la detección temprana de errores, al validar los datos antes de que se procesen en el sistema.
Integración con Python
En Python, existen bibliotecas como jsonschema que permiten validar JSON Objects contra un JSON Schema. A continuación, se muestra un ejemplo de cómo utilizar esta biblioteca:
Instalación de la biblioteca:
pip install jsonschema
Uso de jsonschema para validar un JSON Object:
from jsonschema import validate, ValidationError
json_obj = {
"nombre": "María",
"edad": 30,
"correo": "maria@example.com",
"aficiones": ["lectura", "senderismo", "pintura"]
}
json_schema = {
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "PerfilUsuario",
"type": "object",
"properties": {
"nombre": {
"type": "string"
},
"edad": {
"type": "integer",
"minimum": 0
},
"correo": {
"type": "string",
"format": "email"
},
"aficiones": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": ["nombre", "correo"],
"additionalProperties": False
}
try:
validate(instance=json_obj, schema=json_schema)
print("El JSON Object es válido según el JSON Schema.")
except ValidationError as e:
print("Error de validación:", e.message)
En este ejemplo, se utiliza la función validate para comprobar si el objeto JSON cumple con las reglas definidas en el esquema. Si el objeto no cumple con el esquema, se genera una excepción ValidationError, indicando el motivo del fallo.
Integración con openai
Ejemplo completo de cómo indicar a la API chat de Open AI que queremos una respuesta estructurada con json schema:
import json
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful math tutor. Guide the user through the solution step by step."},
{"role": "user", "content": "how can I solve 8x + 7 = -23"}
],
response_format={
"type": "json_schema",
"json_schema": {
"name": "math_response",
"schema": {
"type": "object",
"properties": {
"steps": {
"type": "array",
"items": {
"type": "object",
"properties": {
"explanation": {"type": "string"},
"output": {"type": "string"}
},
"required": ["explanation", "output"],
"additionalProperties": False
}
},
"final_answer": {"type": "string"}
},
"required": ["steps", "final_answer"],
"additionalProperties": False
},
"strict": True
}
}
)
content_string_json = response.choices[0].message.content
print(content_string_json)
content_json = json.loads(content_string_json)
print(content_json["final_answer"]) # Acceso al valor 'final_answers'
En este ejemplo de código vemos cómo a través del parámetro response_format se indica a la API que queremos una respuesta estructurada.
Procesar JSON Schema con Pydantic en Python
Pydantic es una biblioteca de Python que facilita la validación y el parsing de datos utilizando anotaciones de tipo. Al trabajar con JSON Schema, Pydantic permite definir modelos de datos en Python y validar instancias de JSON contra estos modelos, garantizando que los datos cumplen con la estructura y tipos esperados.
Para comenzar a trabajar con Pydantic, primero debemos instalar la biblioteca. Esto se realiza fácilmente desde el gestor de paquetes pip:
pip install pydantic pydantic[email]
Una vez instalada, Pydantic nos proporciona una sintaxis similar a la de anotaciones de tipo en Python para definir la estructura de datos que esperamos. Este enfoque resulta natural y eficiente al momento de implementar validaciones complejas y específicas para cada campo.
Después, es esencial definir un modelo de datos utilizando Pydantic. Estos modelos se crean como clases que heredan de BaseModel, con atributos que representan las propiedades esperadas en los datos JSON. Cada atributo se anota con su tipo, lo que permite a Pydantic realizar la validación automática.
Por ejemplo:
from pydantic import BaseModel, EmailStr
from typing import List
class Usuario(BaseModel):
nombre: str
edad: int
correo: EmailStr
aficiones: List[str]
En este modelo, la clase Usuario define la estructura de los datos que esperamos recibir. El atributo correo utiliza el tipo EmailStr proporcionado por Pydantic para validar direcciones de correo electrónico.
Una vez definido el modelo, es posible crear instancias del mismo a partir de datos JSON. Pydantic convierte automáticamente los datos y verifica que cumplen con los tipos especificados:
datos_json = {
"nombre": "Lucía",
"edad": 27,
"correo": "lucia@example.com",
"aficiones": ["fotografía", "ciclismo"]
}
usuario = Usuario(**datos_json)
print(usuario)
Este código crea una instancia de Usuario a partir del diccionario datos_json. Si los datos no cumplen con el esquema definido, Pydantic genera excepciones que indican dónde se produjo el error.
Por ejemplo, si el campo edad se proporciona como una cadena en lugar de un entero:
datos_erroneos = {
"nombre": "Carlos",
"edad": "treinta",
"correo": "carlos@example.com",
"aficiones": ["lectura", "ajedrez"]
}
try:
usuario_erroneo = Usuario(**datos_erroneos)
except ValueError as e:
print(e)
Pydantic genera un error de validación, indicando que el valor de edad debe ser un entero.
Además de validar datos, Pydantic puede generar JSON Schema a partir de los modelos definidos. Esto es especialmente útil para documentar APIs y garantizar la compatibilidad con otros sistemas. Para obtener el JSON Schema de un modelo:
# Para obtener el JSON Schema de un modelo
import json
json_schema = Usuario.model_json_schema()
json_schema
Este método genera una representación en formato JSON Schema del modelo Usuario, facilitando la integración y validación en otros entornos.
Pydantic permite manejar campos opcionales utilizando Optional de typing o asignando valores por defecto:
from typing import Optional
class Usuario(BaseModel):
nombre: str
edad: int
correo: EmailStr
aficiones: Optional[List[str]] = None
En este caso, el campo aficiones es opcional y, si no se proporciona, su valor será None.
Al integrar Pydantic con JSON Schema, es posible cargar esquemas externos y generar modelos dinámicamente. Sin embargo, Pydantic no soporta directamente la carga de JSON Schemas para crear modelos, pero herramientas como datamodel-code-generator pueden convertir JSON Schemas en modelos Pydantic.
Para instalar datamodel-code-generator:
pip install datamodel-code-generator
Ahora creamos un archivo schema_usuario.json:
{
"properties": {
"nombre": {
"title": "Nombre",
"type": "string"
},
"edad": {
"title": "Edad",
"type": "integer"
},
"correo": {
"format": "email",
"title": "Correo",
"type": "string"
},
"aficiones": {
"items": {
"type": "string"
},
"title": "Aficiones",
"type": "array"
}
},
"required": [
"nombre",
"edad",
"correo",
"aficiones"
],
"title": "Usuario",
"type": "object"
}
Y utilizarlo para generar el modelo a partir del JSON Schema ejecutamos el siguiente comando por terminal en la misma carpeta donde esté el schema_usuario.json:
datamodel-codegen --input schema_usuario.json --input-file-type jsonschema --output modelo_usuario.py
Esta herramienta analiza el JSON Schema proporcionado y genera las clases Pydantic correspondientes, simplificando el proceso de trabajar con esquemas complejos.
Una vez generado el modelo, se puede utilizar de la misma manera que los modelos definidos manualmente, beneficiándose de las capacidades de validación y parsing de Pydantic.
Pydantic también es compatible con las nuevas características de Python 3.14, como las anotaciones de tipo mejoradas y las funciones asíncronas. Al definir modelos en Python 3.14, se aprovechan las ventajas de los tipos genéricos y las clases de tipos más expresivas.
Por ejemplo, utilizando las nuevas anotaciones:
class Usuario(BaseModel):
nombre: str
edad: int
correo: EmailStr
aficiones: list[str] | None = None
La sintaxis list[str] | None es una forma más concisa de indicar que aficiones puede ser una lista de cadenas o None, aprovechando las mejoras en el sistema de tipos de Python.
Ahora que ya conocemos cómo usar Pydantic, vamos a utilizarlo para obtener una respuesta estructurada usando modelos de Pydantic:
from openai import OpenAI
from pydantic import BaseModel
client = OpenAI()
class Step(BaseModel):
explanation: str
output: str
class MathReasoning(BaseModel):
steps: list[Step]
final_answer: str
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful math tutor. Guide the user through the solution step by step."},
{"role": "user", "content": "how can I solve 8x + 7 = -23"}
],
response_format=MathReasoning,
)
math_reasoning = completion.choices[0].message.parsed
print(math_reasoning)
print(math_reasoning.final_answer)
En este ejemplo primero se crean los modelos extendiendo la clase BaseModel de Pydantic y luego se usan en el parámetro response_format de la API chat de openai. Es posible que el código cambie ligeramente en el momento de lectura de este documento ya que la API está en constante evolución. Ver acceso a la API chat aquí para obtener un código lo más actualizado posible.
Desplegar modelos que soporten salidas estructuradas en Azure OpenAI Service
Para aprovechar las salidas estructuradas de los modelos de IA en Azure OpenAI Service, es necesario desplegar modelos adecuados que permitan esta funcionalidad. A continuación, se detallan los pasos para desplegar un modelo que soporte salidas estructuradas en Azure OpenAI Service.
En primer lugar, es imprescindible contar con una suscripción de Azure y tener acceso al servicio de Azure OpenAI.
Una vez que cuentas con acceso al servicio, el siguiente paso es crear un recurso de Azure OpenAI en tu suscripción. Para ello, inicia sesión en el Portal de Azure y sigue estos pasos:
- Navega al menú de Crear un recurso y busca "Azure OpenAI".
- Selecciona el servicio Azure OpenAI y haz clic en Crear.
- Proporciona los detalles necesarios, como la suscripción, el grupo de recursos y el nombre del recurso.
- Selecciona la ubicación geográfica donde deseas desplegar el servicio.
- Revisa y acepta los términos y condiciones, luego haz clic en Crear para desplegar el recurso.
Una vez creado el recurso, es momento de desplegar el modelo que soporta salidas estructuradas. Sigue estos pasos:
- Accede al recurso de Azure OpenAI que acabas de crear.
- En el menú lateral, selecciona la opción Modelos desplegados.
- Haz clic en Agregar para desplegar un nuevo modelo.
- En el campo Modelo, selecciona un modelo de la lista de modelos disponibles.
- Asigna un nombre de despliegue único que identificará a este modelo en tus aplicaciones.
- Configura los parámetros adicionales según tus necesidades. Estos parámetros incluyen los ajustes de versión del modelo, que determinan la versión específica, y las capacidades que soporta el modelo.
- Revisa la configuración y haz clic en Desplegar para iniciar el proceso.
Ejemplo de panel que aparece al seleccionar desplegar modelo:

Una vez seleccionas el modelo que quieres, te pedirá seleccionar el deployment type y deployment details, donde es probable que si no tenemos quota tengamos que solicitarla. Una vez hecho deberíamos poder confirmar el despliegue:

Es importante destacar que no todos los modelos soportan salidas estructuradas, por lo que es necesario revisar la documentación oficial de Microsoft Azure para comprobar qué modelos las permiten: https://learn.microsoft.com/es-es/azure/ai-services/openai/how-to/structured-outputs?tabs=python-secure#supported-models
Una vez tenemos el modelo desplegado veremos que nos proporciona un endpoint y una clave, además de dos datos del despliegue:

Podemos usar esta información para conectarnos desde código Python y probar las salidas estructuradas.
En este ejemplo se utiliza el modelo desplegado desde la biblioteca openai a través de Azure:
from pydantic import BaseModel
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint="https://azure-openai-testing.openai.azure.com/openai/deployments/gpt-4o-mini/chat/completions?api-version=2024-08-01-preview",
api_key="ESCRIBE_AQUI_TU_API_KEY",
api_version="2024-08-01-preview",
)
class CalendarEvent(BaseModel):
name: str
date: str
participants: list[str]
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Extract the event information."},
{"role": "user", "content": "Alice and Bob are going to a science fair on Friday."},
],
response_format=CalendarEvent,
)
event = completion.choices[0].message.parsed
event
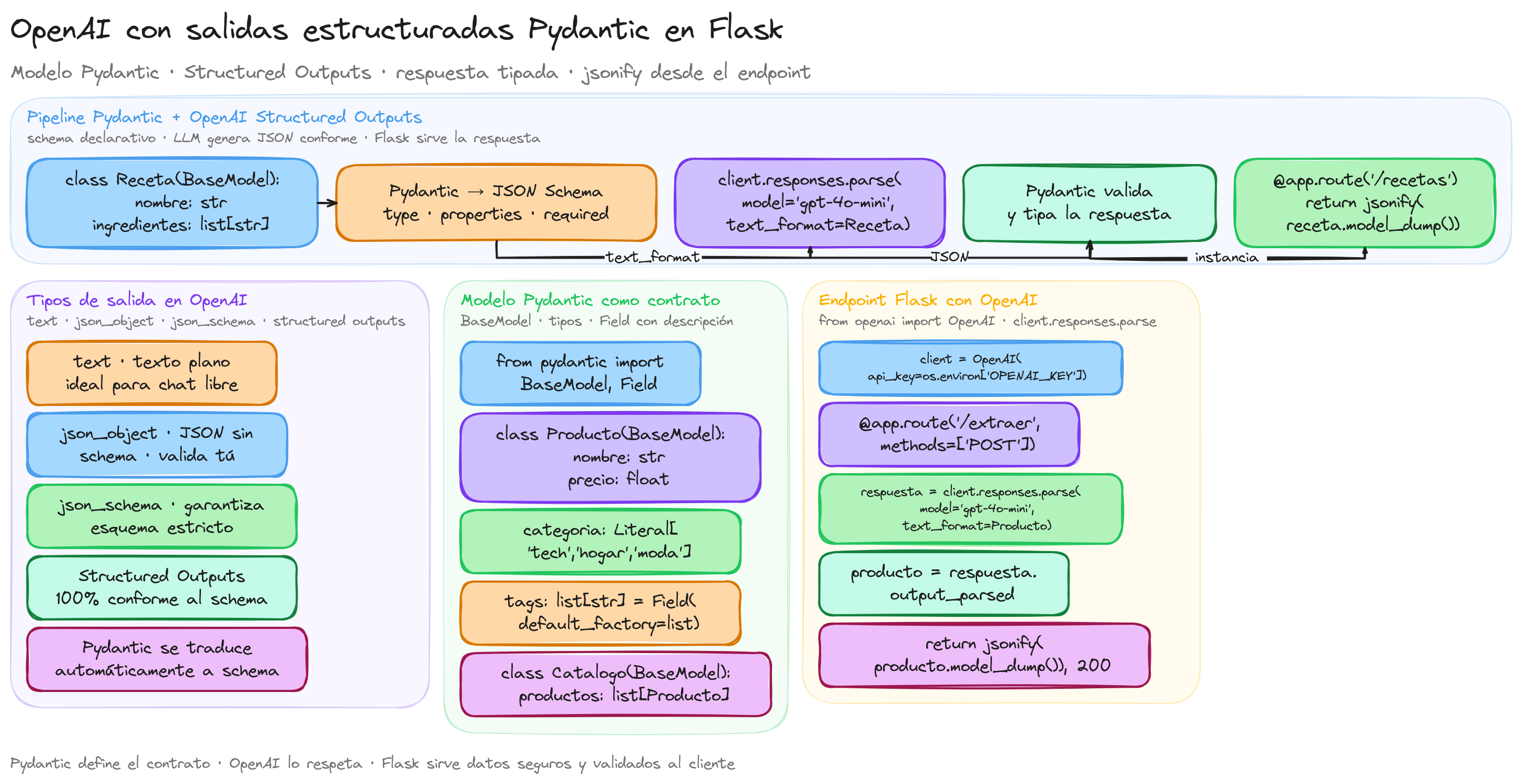
Integración de Pydantic y openai en Flask para obtener salidas JSON Schema
Para poder utilizar los conocimientos aprendidos en una aplicación web, vamos a probar a integrar Pydantic y openai en Flask, un microframework de Python para construir microservicios y aplicaciones backend.
Flask es un framework de desarrollo web minimalista y ligero en Python diseñado para crear aplicaciones web rápidas y sencillas. Fue desarrollado por Armin Ronacher y forma parte del proyecto Pocoo. Su filosofía se basa en ser simple, extensible y flexible, proporcionándole al desarrollador control total sobre la arquitectura de la aplicación sin imponer muchas restricciones.
Instalamos las librerías necesarias para este ejemplo:
pip install flask pydantic openai
Después, creamos un archivo app.py donde introduciremos el siguiente código python:
from flask import Flask, request
from openai import OpenAI
from pydantic import BaseModel, ValidationError
client = OpenAI()
class Step(BaseModel):
explanation: str
output: str
class MathReasoning(BaseModel):
steps: list[Step]
final_answer: str
app = Flask(__name__)
@app.route('/solve', methods=['POST'])
def solve_math_problem():
try:
data = request.json
question = data.get("question", None)
if not question:
return {"error": "No se proporcionó una pregunta"}, 400
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful math tutor. Guide the user through the solution step by step."},
{"role": "user", "content": question}
],
response_format=MathReasoning,
)
math_reasoning = completion.choices[0].message.parsed
return math_reasoning.model_dump(), 200
except ValidationError as e:
return {"error": "Error de validación en los datos devueltos por OpenAI", "details": e.errors()}, 500
except Exception as e:
return {"error": str(e)}, 500
if __name__ == '__main__':
app.run(debug=True)
Este código crea una aplicación en Flask de un solo método, que recibe una pregunta para resolver una ecuación matemática y con la ayuda de la API de openai la resuelve y devuelve la respuesta en json indicando la resolución paso a paso.
Para probarlo primero ejecutamos la aplicación con el comando en el mismo directorio donde esté el archivo:
python app.py
Una vez arrancada, podemos lanzar la petición POST para probarla tanto desde terminal con curl como desde clientes HTTP como por ejemplo Postman:

De esta forma hemos creado una aplicación sencilla que se comunica con la API de OpenAI, si queremos que lo haga a través de Azure OpenAI Service solo tendremos que reemplazar la clase OpenAI por AzureOpenAI y las credenciales.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Flask es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Flask
Explora más contenido relacionado con Flask y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Desplegar modelos LLM de IA en Azure OpenAI Service. Obtener salidas estructuradas de modelos de IA utilizando Pydantic. Utilizar modelos de IA en Flask.