Instalación de Flask-Marshmallow y creación de esquemas de serialización
Para integrar Flask-Marshmallow en nuestra aplicación, es esencial instalar los paquetes necesarios. Ejecuta el siguiente comando en tu entorno virtual para instalar flask-marshmallow, marshmallow y marshmallow-sqlalchemy:
pip install flask-marshmallow marshmallow marshmallow-sqlalchemy
Una vez instalados, podemos configurar Flask-Marshmallow en nuestra aplicación Flask. Primero, importamos las bibliotecas y creamos instancias de Flask, SQLAlchemy y Marshmallow:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+mysqlconnector://usuario:contraseña@localhost/nombre_base_datos'
db = SQLAlchemy(app)
ma = Marshmallow(app)
Supongamos que tenemos un modelo Usuario definido con SQLAlchemy:
class Usuario(db.Model):
id = db.Column(db.Integer, primary_key=True)
nombre = db.Column(db.String(100), unique=True)
email = db.Column(db.String(100), unique=True)
contraseña = db.Column(db.String(200))
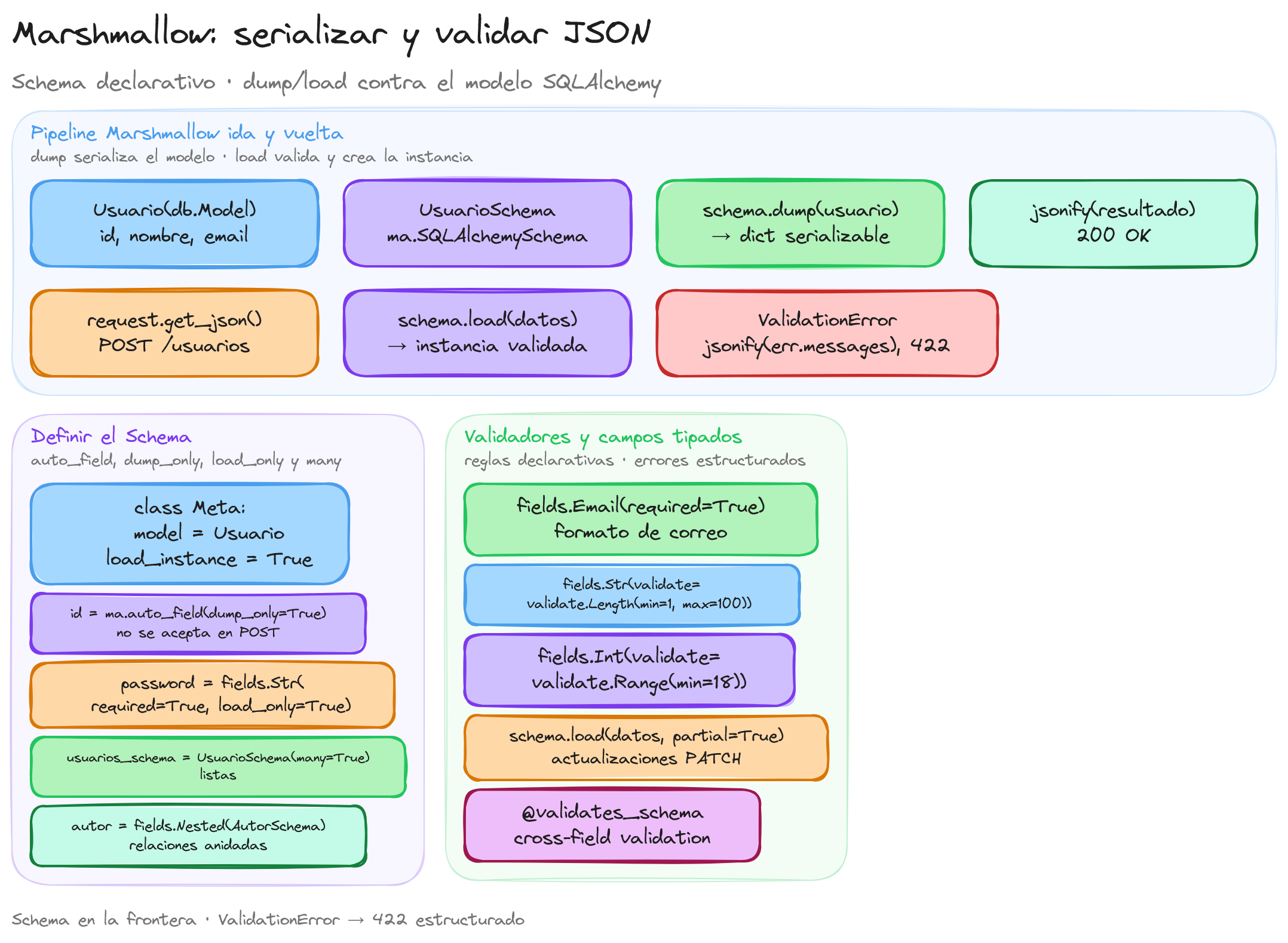
Para poder serializar este modelo, creamos un esquema con Marshmallow. Los esquemas definen cómo se transforman los objetos del modelo en representaciones serializables, como JSON:
class UsuarioSchema(ma.SQLAlchemySchema):
class Meta:
model = Usuario
load_instance = True
id = ma.auto_field()
nombre = ma.auto_field()
email = ma.auto_field()
En este esquema, usamos auto_field() para generar automáticamente los campos en función de los atributos del modelo. La opción load_instance = True permite cargar instancias del modelo al deserializar los datos.
Crearemos instancias del esquema para utilizarlo en nuestra aplicación:
usuario_schema = UsuarioSchema()
usuarios_schema = UsuarioSchema(many=True)
- usuario_schema: para serializar y deserializar una única instancia de Usuario.
- usuarios_schema: para serializar y deserializar múltiples instancias.
Ahora, podemos serializar un objeto Usuario a formato JSON:
@app.route('/usuario/<int:id>', methods=['GET'])
def obtener_usuario(id):
usuario = Usuario.query.get(id)
if usuario:
resultado = usuario_schema.dump(usuario)
return jsonify(resultado)
else:
return jsonify({'mensaje': 'Usuario no encontrado'}), 404
Para serializar una lista de usuarios:
@app.route('/usuarios', methods=['GET'])
def obtener_usuarios():
usuarios = Usuario.query.all()
resultado = usuarios_schema.dump(usuarios)
return jsonify(resultado)
De esta manera, las respuestas de nuestros endpoints REST están correctamente serializadas, facilitando la comunicación con clientes y otras aplicaciones.
También es posible definir métodos adicionales en el esquema para personalizar la serialización. Por ejemplo, podemos ocultar la contraseña al serializar:
class UsuarioSchema(ma.SQLAlchemySchema):
class Meta:
model = Usuario
load_instance = True
id = ma.auto_field()
nombre = ma.auto_field()
email = ma.auto_field()
contraseña = ma.auto_field(load_only=True)
El parámetro load_only=True indica que el campo contraseña se utiliza solo al deserializar (por ejemplo, al crear un nuevo usuario), pero no se incluye al serializar.
Para crear un nuevo usuario y deserializar los datos de entrada:
@app.route('/usuario', methods=['POST'])
def crear_usuario():
datos = request.get_json()
try:
usuario = usuario_schema.load(datos, session=db.session)
db.session.add(usuario)
db.session.commit()
return usuario_schema.dump(usuario), 201
except ValidationError as err:
return jsonify(err.messages), 400
En este ejemplo, utilizamos load() para deserializar los datos de entrada y crear una instancia de Usuario. Si hay errores de validación, se devuelven al cliente.
Gracias a Flask-Marshmallow, podemos manejar de forma eficiente la serialización y deserialización de nuestros modelos, garantizando que los datos intercambiados en la API REST sean consistentes y estén validados correctamente.
Validación de datos de entrada
El manejo adecuado de los datos de entrada es crucial en el desarrollo de una API REST. Marshmallow facilita la validación de datos, asegurando que la información recibida cumpla con los requisitos establecidos.
Para validar los datos entrantes, se utilizan los esquemas de Marshmallow con campos y validadores específicos. Por ejemplo, consideremos un esquema para una entidad Usuario que espera recibir un nombre, un correo electrónico y una contraseña:
from marshmallow import fields, validate
class UsuarioSchema(ma.SQLAlchemySchema):
class Meta:
model = Usuario
load_instance = True
id = ma.auto_field(dump_only=True)
nombre = fields.String(required=True, validate=validate.Length(min=1, max=100))
email = fields.Email(required=True, validate=validate.Email())
contraseña = fields.String(required=True, load_only=True, validate=validate.Length(min=8))
En este esquema:
- El campo nombre es obligatorio (required=True) y debe tener una longitud entre 1 y 100 caracteres.
- El campo email utiliza el validador Email, asegurando que el formato corresponda a una dirección de correo electrónico válida.
- El campo contraseña también es obligatorio, se marca como load_only para que no se serialice en las respuestas, y debe tener al menos 8 caracteres.
Al definir validadores, garantizamos que los datos proporcionados cumplen con las condiciones necesarias antes de ser procesados.
Para manejar la validación en una ruta POST, se utiliza el método load() del esquema:
from flask import request, jsonify
from marshmallow import ValidationError
@app.route('/usuarios', methods=['POST'])
def crear_usuario():
json_data = request.get_json()
if not json_data:
return jsonify({'mensaje': 'No se proporcionaron datos'}), 400
try:
datos_validados = usuario_schema.load(json_data)
except ValidationError as err:
return jsonify({'errores': err.messages}), 422
nuevo_usuario = Usuario(
nombre=datos_validados['nombre'],
email=datos_validados['email'],
contraseña=generar_hash(datos_validados['contraseña'])
)
db.session.add(nuevo_usuario)
db.session.commit()
resultado = usuario_schema.dump(nuevo_usuario)
return jsonify({'usuario': resultado}), 201
En este ejemplo:
- Se verifica si json_data contiene información; si no, se devuelve un código de estado 400.
- Se intenta cargar y validar los datos utilizando usuario_schema.load().
- Si hay errores de validación, se capturan y se devuelven con un código de estado 422 (Entidad no procesable).
- Si los datos son válidos, se crea una nueva instancia de Usuario, se agrega a la sesión y se confirma la transacción.
- Se devuelve el usuario creado, serializado mediante usuario_schema.dump().
Es fundamental manejar las excepciones de ValidationError para informar al cliente sobre los errores específicos en los datos enviados.
Además, es posible definir validadores personalizados para campos específicos. Por ejemplo, para asegurarse de que el nombre de usuario no contenga espacios:
def no_tiene_espacios(valor):
if ' ' in valor:
raise ValidationError('El nombre de usuario no debe contener espacios.')
class UsuarioSchema(ma.SQLAlchemySchema):
class Meta:
model = Usuario
load_instance = True
id = ma.auto_field(dump_only=True)
nombre = fields.String(
required=True,
validate=[
validate.Length(min=1, max=100),
no_tiene_espacios
]
)
email = fields.Email(required=True)
contraseña = fields.String(required=True, load_only=True, validate=validate.Length(min=8))
Aquí, el validador personalizado no_tiene_espacios se agrega al campo nombre, proporcionando una validación adicional específica.
También se pueden implementar validaciones a nivel de esquema para condiciones que involucran múltiples campos. Por ejemplo, para confirmar que la contraseña y su confirmación coinciden:
from marshmallow import validates_schema
class RegistroUsuarioSchema(ma.SQLAlchemySchema):
class Meta:
model = Usuario
load_instance = True
nombre = fields.String(required=True)
email = fields.Email(required=True)
contraseña = fields.String(required=True, load_only=True)
confirmar_contraseña = fields.String(required=True, load_only=True)
@validates_schema
def validar_contraseñas(self, datos, **kwargs):
if datos['contraseña'] != datos['confirmar_contraseña']:
raise ValidationError('Las contraseñas no coinciden.', field_name='confirmar_contraseña')
Utilizando @validates_schema, se puede acceder a todos los datos y aplicar validaciones que dependan de múltiples campos simultáneamente.
Al integrar la validación con métodos PUT o PATCH, se puede permitir la actualización parcial de datos utilizando el parámetro partial=True:
@app.route('/usuario/<int:id>', methods=['PUT'])
def actualizar_usuario(id):
usuario = Usuario.query.get_or_404(id)
json_data = request.get_json()
if not json_data:
return jsonify({'mensaje': 'No se proporcionaron datos'}), 400
try:
datos_actualizados = usuario_schema.load(json_data, instance=usuario, partial=True)
except ValidationError as err:
return jsonify({'errores': err.messages}), 422
db.session.commit()
resultado = usuario_schema.dump(datos_actualizados)
return jsonify({'usuario': resultado}), 200
El uso de partial=True permite que solo se validen los campos proporcionados en la solicitud, facilitando actualizaciones parciales sin necesidad de enviar todos los campos del modelo.
Es importante proporcionar mensajes de error claros y específicos para facilitar al cliente la corrección de los datos enviados. Esto mejora la usabilidad de la API y reduce la probabilidad de errores en solicitudes futuras.
Serialización de modelos a JSON
La serialización es el proceso de convertir objetos complejos en formatos sencillos de transmitir, como JSON. En una API REST, es fundamental serializar correctamente los modelos para enviar respuestas coherentes y completas a los clientes. Con Marshmallow y Flask-Marshmallow, podemos personalizar la serialización de nuestros modelos y manejar relaciones entre ellos de manera eficiente.
Cuando nuestros modelos tienen relaciones, como ForeignKey o relationship de SQLAlchemy, es necesario reflejar estas conexiones al serializar. Marshmallow permite anidar esquemas para serializar relaciones. Supongamos que tenemos dos modelos: Autor y Libro, donde un autor puede tener múltiples libros.
class Autor(db.Model):
id = db.Column(db.Integer, primary_key=True)
nombre = db.Column(db.String(100), nullable=False)
libros = db.relationship('Libro', backref='autor', lazy=True)
class Libro(db.Model):
id = db.Column(db.Integer, primary_key=True)
titulo = db.Column(db.String(200), nullable=False)
autor_id = db.Column(db.Integer, db.ForeignKey('autor.id'), nullable=False)
Para serializar un Libro incluyendo información del Autor, definimos los esquemas con esquemas anidados:
class AutorSchema(ma.SQLAlchemySchema):
class Meta:
model = Autor
load_instance = True
id = ma.auto_field()
nombre = ma.auto_field()
class LibroSchema(ma.SQLAlchemySchema):
class Meta:
model = Libro
load_instance = True
id = ma.auto_field()
titulo = ma.auto_field()
autor = ma.Nested(AutorSchema)
Al usar ma.Nested(AutorSchema) en el campo autor, indicamos que al serializar un Libro, incluiremos los datos del Autor utilizando el esquema correspondiente. Por ejemplo, en una ruta podemos utilizar:
libro_schema = LibroSchema()
@app.route('/libro/<int:id>', methods=['GET'])
def obtener_libro(id):
libro = Libro.query.get_or_404(id)
resultado = libro_schema.dump(libro)
return jsonify(resultado)
La respuesta JSON incluirá los datos del libro y, dentro del campo autor, los datos del autor asociado:
{
"id": 1,
"titulo": "El Quijote",
"autor": {
"id": 1,
"nombre": "Miguel de Cervantes"
}
}
Al serializar relaciones bidireccionales, existe el riesgo de entrar en bucles infinitos. Para evitarlo, podemos controlar la profundidad de anidación o utilizar la opción exclude. Si también queremos anidar los libros al serializar un Autor, modificamos el AutorSchema:
class AutorSchema(ma.SQLAlchemySchema):
class Meta:
model = Autor
load_instance = True
id = ma.auto_field()
nombre = ma.auto_field()
libros = ma.Nested('LibroSchema', many=True, exclude=('autor',))
Aquí, utilizamos una cadena de texto para referenciar LibroSchema, y en exclude indicamos que excluimos el campo autor dentro de libros para evitar la recursión.
Marshmallow permite añadir campos calculados o personalizados mediante Method o Function. Por ejemplo, si queremos incluir un nuevo campo titulo_mayusculas en el LibroSchema, podemos hacer lo siguiente:
class LibroSchema(ma.SQLAlchemySchema):
class Meta:
model = Libro
load_instance = True
id = ma.auto_field()
titulo = ma.auto_field()
autor = ma.Nested(AutorSchema)
titulo_mayusculas = ma.Method('obtener_titulo_mayusculas')
def obtener_titulo_mayusculas(self, obj):
return obj.titulo.upper()
El campo titulo_mayusculas se calculará en tiempo de serialización utilizando el método obtener_titulo_mayusculas. Esto nos permite añadir información adicional o transformada en la salida JSON.
En ocasiones, es útil serializar solo ciertos campos dependiendo del contexto. Marshmallow permite personalizar qué campos incluir o excluir en tiempo de ejecución. Por ejemplo, creamos una función para generar el esquema con los campos deseados:
def crear_libro_schema(excluir_campos=None):
class DynamicLibroSchema(ma.SQLAlchemySchema):
class Meta:
model = Libro
load_instance = True
id = ma.auto_field()
titulo = ma.auto_field()
autor = ma.Nested(AutorSchema)
if excluir_campos:
for campo in excluir_campos:
del locals()[campo]
return DynamicLibroSchema()
Podemos utilizar este esquema dinámico en una ruta para controlar los campos incluidos en la serialización:
@app.route('/libro_simple/<int:id>', methods=['GET'])
def obtener_libro_simple(id):
libro = Libro.query.get_or_404(id)
libro_schema = crear_libro_schema(excluir_campos=['autor'])
resultado = libro_schema.dump(libro)
return jsonify(resultado)
De esta forma, podemos adaptar la serialización a las necesidades específicas del endpoint, excluyendo o incluyendo campos según sea necesario.
Al devolver listas extensas de registros, es recomendable implementar paginación para mejorar el rendimiento y la usabilidad. Combinamos la paginación con la serialización:
from flask_sqlalchemy import Pagination
@app.route('/libros', methods=['GET'])
def obtener_libros():
pagina = request.args.get('pagina', 1, type=int)
tamano_pagina = request.args.get('tamano_pagina', 10, type=int)
paginacion = Libro.query.paginate(page=pagina, per_page=tamano_pagina, error_out=False)
libros_schema = LibroSchema(many=True)
resultado = libros_schema.dump(paginacion.items)
respuesta = {
'total': paginacion.total,
'pagina': paginacion.page,
'paginas': paginacion.pages,
'libros': resultado
}
return jsonify(respuesta)
Incluimos información de la paginación junto con los datos serializados, mejorando la eficiencia de nuestras respuestas y permitiendo al cliente manejar los datos de manera óptima.
En ocasiones, necesitamos separar los campos utilizados para serializar de los utilizados para deserializar. Podemos definir esquemas diferentes o utilizar las opciones dump_only y load_only. Por ejemplo:
class LibroSchema(ma.SQLAlchemySchema):
class Meta:
model = Libro
load_instance = True
id = ma.auto_field(dump_only=True)
titulo = ma.auto_field(required=True)
autor_id = ma.auto_field(required=True, load_only=True)
autor = ma.Nested(AutorSchema, dump_only=True)
- id: solo se incluye al serializar (dump_only).
- titulo: requerido tanto al serializar como al deserializar.
- autor_id: requerido al deserializar, pero no se incluye al serializar (load_only).
- autor: se incluye al serializar, pero no se espera al deserializar.
Si nuestro modelo incluye campos de fecha u otros tipos complejos, podemos definir cómo se serializan. Por ejemplo, para un modelo Evento:
class Evento(db.Model):
id = db.Column(db.Integer, primary_key=True)
nombre = db.Column(db.String(100), nullable=False)
fecha = db.Column(db.DateTime, nullable=False)
class EventoSchema(ma.SQLAlchemySchema):
class Meta:
model = Evento
load_instance = True
id = ma.auto_field()
nombre = ma.auto_field()
fecha = fields.DateTime(format='%Y-%m-%d %H:%M:%S')
Al especificar el format en fields.DateTime, controlamos la representación de la fecha en el JSON, asegurando consistencia en el formato de las fechas en las respuestas.
Podemos definir opciones en la clase Meta del esquema para personalizar el comportamiento. Por ejemplo, establecer ordered = True garantiza que los campos se serialicen en el orden definido, lo cual puede ser importante para algunos clientes:
class LibroSchema(ma.SQLAlchemySchema):
class Meta:
model = Libro
load_instance = True
ordered = True
id = ma.auto_field()
titulo = ma.auto_field()
autor = ma.Nested(AutorSchema)
Para evitar problemas de rendimiento al serializar relaciones, es importante optimizar las consultas utilizando join y options de SQLAlchemy. Por ejemplo:
from sqlalchemy.orm import joinedload
@app.route('/libros_optimizados', methods=['GET'])
def obtener_libros_optimizados():
libros = Libro.query.options(joinedload(Libro.autor)).all()
libros_schema = LibroSchema(many=True)
resultado = libros_schema.dump(libros)
return jsonify(resultado)
Al usar joinedload, cargamos el Autor asociado en la misma consulta, reduciendo el número de accesos a la base de datos y mejorando el rendimiento.
Si necesitamos modificar los datos antes de serializarlos, podemos utilizar @pre_dump. Por ejemplo, si queremos calcular la edad de un usuario antes de serializarlo:
from marshmallow import pre_dump
class UsuarioSchema(ma.SQLAlchemySchema):
class Meta:
model = Usuario
load_instance = True
id = ma.auto_field()
nombre = ma.auto_field()
edad = ma.Integer()
@pre_dump
def calcular_edad(self, obj, **kwargs):
obj.edad = calcular_edad_desde_fecha(obj.fecha_nacimiento)
return obj
Aquí, antes de la serialización, calculamos la edad del usuario a partir de su fecha de nacimiento y la añadimos al objeto.
La serialización de modelos a JSON con Marshmallow en Flask ofrece una amplia flexibilidad y potencia. Podemos manejar relaciones complejas, personalizar la salida, optimizar el rendimiento y garantizar que nuestras API REST proporcionen datos consistentes y bien estructurados. Aplicando estas técnicas avanzadas, mejoramos la calidad y eficiencia de nuestras aplicaciones.
Integración de Marshmallow en endpoints REST
Integrar Marshmallow en los endpoints REST de una aplicación Flask permite manejar de manera eficiente la serialización y validación de datos en las rutas de la API. A continuación, exploraremos cómo utilizar los esquemas de Marshmallow en distintos métodos HTTP y cómo optimizar su uso en nuestros endpoints.
Uso de esquemas en métodos GET
En un endpoint que responde a una petición GET, utilizamos los esquemas de Marshmallow para serializar los datos que se enviarán al cliente. Por ejemplo, para obtener una lista de usuarios:
@app.route('/usuarios', methods=['GET'])
def obtener_usuarios():
usuarios = Usuario.query.all()
resultado = usuarios_schema.dump(usuarios)
return jsonify(resultado)
En este caso, usuarios_schema es una instancia de UsuarioSchema con el parámetro many=True, lo que permite serializar múltiples objetos. La función dump() transforma los objetos usuarios en un formato compatible con JSON.
Si se necesita obtener un usuario específico:
@app.route('/usuarios/<int:id>', methods=['GET'])
def obtener_usuario(id):
usuario = Usuario.query.get_or_404(id)
resultado = usuario_schema.dump(usuario)
return jsonify(resultado)
Aquí, usuario_schema es una instancia de UsuarioSchema para un solo objeto. La función get_or_404() devuelve el objeto si existe o un error 404 si no se encuentra.
Manejo de datos de entrada en métodos POST
En un endpoint POST, donde se reciben datos del cliente, Marshmallow facilita la deserialización y validación de los datos entrantes.
@app.route('/usuarios', methods=['POST'])
def crear_usuario():
datos = request.get_json()
if not datos:
return jsonify({'mensaje': 'No se proporcionaron datos'}), 400
try:
nuevo_usuario = usuario_schema.load(datos)
except ValidationError as err:
return jsonify({'errores': err.messages}), 422
db.session.add(nuevo_usuario)
db.session.commit()
resultado = usuario_schema.dump(nuevo_usuario)
return jsonify(resultado), 201
En este ejemplo:
- Se obtiene el JSON del cuerpo de la solicitud.
- Se utiliza usuario_schema.load() para deserializar y validar los datos. Si hay errores, se devuelven con un código 422.
- Si los datos son válidos, se crea una nueva instancia de Usuario, se guarda en la base de datos y se devuelve la representación serializada.
La validación automática proporciona una mayor seguridad y consistencia en los datos manejados por la aplicación.
Actualización de recursos con métodos PUT y PATCH
Para modificar recursos existentes, se utilizan los métodos PUT y PATCH. Con Marshmallow, es sencillo manejar los datos entrantes y actualizar los objetos correspondientes.
@app.route('/usuarios/<int:id>', methods=['PUT'])
def actualizar_usuario(id):
usuario = Usuario.query.get_or_404(id)
datos = request.get_json()
if not datos:
return jsonify({'mensaje': 'No se proporcionaron datos'}), 400
try:
usuario_actualizado = usuario_schema.load(datos, instance=usuario)
except ValidationError as err:
return jsonify({'errores': err.messages}), 422
db.session.commit()
resultado = usuario_schema.dump(usuario_actualizado)
return jsonify(resultado), 200
Al utilizar el parámetro instance=usuario, Marshmallow actualiza el objeto existente con los datos proporcionados. Para actualizaciones parciales con PATCH, se añade el parámetro partial=True:
@app.route('/usuarios/<int:id>', methods=['PATCH'])
def modificar_usuario(id):
usuario = Usuario.query.get_or_404(id)
datos = request.get_json()
if not datos:
return jsonify({'mensaje': 'No se proporcionaron datos'}), 400
try:
usuario_modificado = usuario_schema.load(datos, instance=usuario, partial=True)
except ValidationError as err:
return jsonify({'errores': err.messages}), 422
db.session.commit()
resultado = usuario_schema.dump(usuario_modificado)
return jsonify(resultado), 200
El uso de partial=True permite validar y actualizar únicamente los campos proporcionados, manteniendo los demás sin cambios.
Eliminación de recursos con métodos DELETE
Para eliminar un recurso, se implementa un endpoint con el método DELETE:
@app.route('/usuarios/<int:id>', methods=['DELETE'])
def eliminar_usuario(id):
usuario = Usuario.query.get_or_404(id)
db.session.delete(usuario)
db.session.commit()
return jsonify({'mensaje': 'Usuario eliminado'}), 200
Aunque en este caso no se utiliza Marshmallow directamente, mantener una estructura consistente en los endpoints facilita el mantenimiento y la comprensión del código.
Manejo global de errores de validación
Marshmallow permite definir un manejador global para los ValidationError, optimizando el manejo de errores en la aplicación:
@app.errorhandler(ValidationError)
def manejar_errores_validacion(error):
return jsonify({'errores': error.messages}), 422
Con este manejador, cualquier error de validación será capturado y se devolverá una respuesta uniforme al cliente.
Anidamiento de esquemas para relaciones
Cuando los modelos tienen relaciones, es posible anidar esquemas para incluir información relacionada en las respuestas. Por ejemplo, si un Usuario tiene múltiples Pedidos:
class PedidoSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = Pedido
load_instance = True
class UsuarioSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = Usuario
load_instance = True
pedidos = fields.Nested(PedidoSchema, many=True)
Al serializar un Usuario, se incluirán sus pedidos serializados según PedidoSchema:
@app.route('/usuarios/<int:id>', methods=['GET'])
def obtener_usuario_con_pedidos(id):
usuario = Usuario.query.get_or_404(id)
resultado = usuario_schema.dump(usuario)
return jsonify(resultado), 200
Esta estructura proporciona una vista completa de los datos relacionados, mejorando la experiencia del cliente de la API.
Autenticación y autorización en endpoints
Integrando Flask-JWT-Extended con Marshmallow, es posible proteger rutas y manejar la autenticación de usuarios:
from flask_jwt_extended import jwt_required, get_jwt_identity
@app.route('/perfil', methods=['GET'])
@jwt_required()
def obtener_perfil():
usuario_id = get_jwt_identity()
usuario = Usuario.query.get_or_404(usuario_id)
resultado = usuario_schema.dump(usuario)
return jsonify(resultado), 200
El decorador @jwt_required() asegura que solo usuarios autenticados puedan acceder al endpoint, y Marshmallow se encarga de serializar los datos del usuario.
Uso de contexto en esquemas
Marshmallow permite pasar un contexto a los esquemas para adaptar la serialización según las necesidades:
class UsuarioSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = Usuario
load_instance = True
email = fields.Email()
@post_dump(pass_original=True)
def ocultar_email(self, data, original_data, **kwargs):
if not self.context.get('mostrar_email', False):
data.pop('email', None)
return data
En el endpoint, se pasa el contexto al serializar:
@app.route('/usuarios/<int:id>', methods=['GET'])
def obtener_usuario(id):
usuario = Usuario.query.get_or_404(id)
contexto = {'mostrar_email': usuario.id == current_user.id}
resultado = usuario_schema.dump(usuario, context=contexto)
return jsonify(resultado), 200
Esto permite controlar qué campos se incluyen en la respuesta según condiciones específicas, añadiendo flexibilidad a la serialización.
Respuestas consistentes con esquemas personalizados
Para estandarizar las respuestas, se pueden crear esquemas personalizados:
class RespuestaSchema(Schema):
mensaje = fields.Str()
datos = fields.Dict()
respuesta_schema = RespuestaSchema()
En un endpoint:
@app.route('/usuarios', methods=['POST'])
def crear_usuario():
# Proceso de creación del usuario...
respuesta = {
'mensaje': 'Usuario creado exitosamente',
'datos': usuario_schema.dump(nuevo_usuario)
}
return respuesta_schema.dump(respuesta), 201
Este enfoque asegura que todas las respuestas sigan un formato común, mejorando la consistencia de la API.
Optimización de consultas y rendimiento
Al integrar Marshmallow en los endpoints, es importante optimizar las consultas para evitar sobrecargas en la base de datos:
from sqlalchemy.orm import joinedload
@app.route('/usuarios/<int:id>', methods=['GET'])
def obtener_usuario_optimo(id):
usuario = Usuario.query.options(joinedload('pedidos')).get_or_404(id)
resultado = usuario_schema.dump(usuario)
return jsonify(resultado), 200
El uso de joinedload() mejora el rendimiento al cargar las relaciones en la misma consulta, reduciendo el número de accesos a la base de datos.
Validaciones adicionales y respuestas claras
Además de las validaciones en los esquemas, se pueden realizar comprobaciones adicionales en los endpoints:
@app.route('/usuarios', methods=['POST'])
def crear_usuario():
# Validación con Marshmallow...
if Usuario.query.filter_by(email=nuevo_usuario.email).first():
return jsonify({'errores': {'email': ['El email ya está en uso']}}), 409
# Guardar el usuario...
Proporcionar mensajes de error claros y códigos de estado HTTP adecuados mejora la usabilidad de la API y facilita la corrección de errores por parte del cliente.
Paginación y filtros en respuestas
Para manejar listas extensas de datos, implementar paginación y filtros es esencial:
@app.route('/productos', methods=['GET'])
def obtener_productos():
pagina = request.args.get('pagina', 1, type=int)
tamano_pagina = request.args.get('tamano_pagina', 20, type=int)
productos = Producto.query.paginate(page=pagina, per_page=tamano_pagina, error_out=False)
resultado = productos_schema.dump(productos.items)
respuesta = {
'total': productos.total,
'pagina': productos.page,
'paginas': productos.pages,
'datos': resultado
}
return jsonify(respuesta), 200
Utilizando productos_schema (instancia de ProductoSchema con many=True), se serializa la lista de productos y se proporciona información de paginación, mejorando la eficiencia en el consumo de la API.
Configuración global y buenas prácticas
Definir una clase base para los esquemas permite centralizar configuraciones y aplicar buenas prácticas:
class BaseSchema(ma.SQLAlchemyAutoSchema):
class Meta:
load_instance = True
sql_session = db.session
include_fk = True
ordered = True
Al heredar de BaseSchema, todos los esquemas mantienen una configuración consistente:
class UsuarioSchema(BaseSchema):
class Meta(BaseSchema.Meta):
model = Usuario
Este enfoque facilita el mantenimiento y asegura que los esquemas compartan las mismas configuraciones y convenciones.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Flask es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Flask
Explora más contenido relacionado con Flask y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Instalar y configurar Flask-Marshmallow.
- Crear y aplicar esquemas de serialización* con Marshmallow.
- Implementar validación de datos de entrada en API REST.
- Generar esquemas personalizados para serializar modelos de base de datos a JSON.
- Anidar esquemas* para manejar relaciones entre modelos.
- Utilizar esquemas en métodos HTTP: GET, POST, PUT, PATCH y DELETE.
- Optimizar el rendimiento de consultas en endpoints REST.
- Emplear técnicas de paginación y filtros para gestionar listas de datos grandes.