Instalación y configuración de Alembic
Alembic es la herramienta estándar para gestionar migraciones de base de datos en proyectos que utilizan SQLAlchemy. Cuando desarrollamos aplicaciones web, es inevitable que necesitemos modificar la estructura de nuestra base de datos: agregar nuevas tablas, cambiar columnas existentes o crear nuevas relaciones entre modelos.
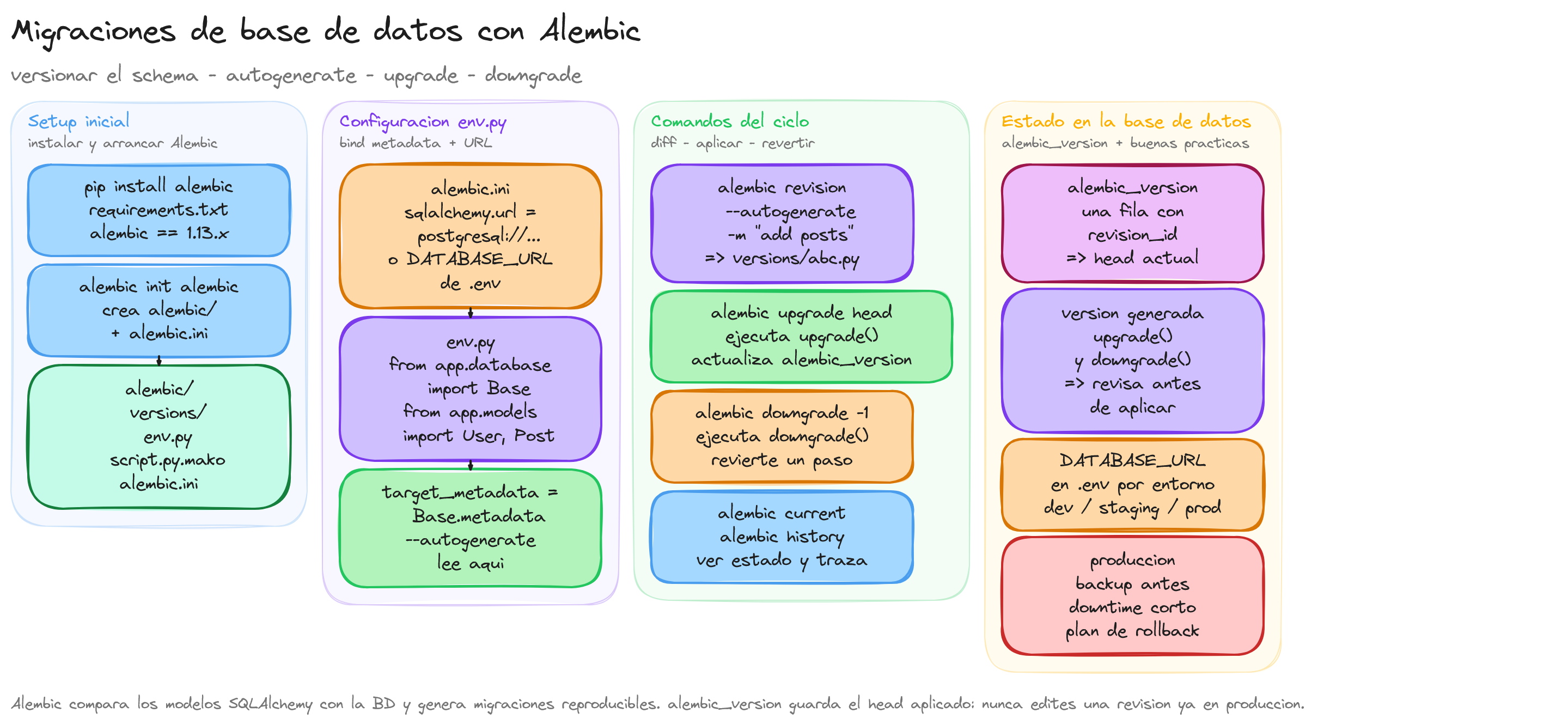
El siguiente diagrama resume visualmente los conceptos clave introducidos en esta sección:
flowchart LR
A[alembic init alembic] --> B["alembic.ini + env.py"]
B --> C[Bind metadata SQLAlchemy]
D[alembic revision --autogenerate] --> E["Migración versions/"]
F[alembic upgrade head] --> G[Aplica BD]
H[alembic downgrade -1] --> I[Revierte]
J[alembic_version tabla] --> G
Sin una herramienta de migraciones, estos cambios pueden resultar en pérdida de datos o inconsistencias entre diferentes entornos de desarrollo. Alembic nos permite versionar los cambios de nuestra base de datos de forma controlada y reproducible.
Instalación de Alembic
Para comenzar a trabajar con Alembic en nuestro proyecto FastAPI, necesitamos instalarlo junto con las dependencias necesarias:
pip install alembic
Si estás trabajando con un archivo requirements.txt, agrega la siguiente línea:
alembic==1.13.1
Alembic se integra perfectamente con SQLAlchemy, por lo que no necesitamos dependencias adicionales si ya tenemos configurado nuestro ORM.
Inicialización del proyecto Alembic
Una vez instalado, debemos inicializar Alembic en nuestro proyecto. Desde la raíz de nuestro proyecto FastAPI, ejecutamos:
alembic init alembic
Este comando crea la siguiente estructura de directorios:
mi_proyecto/
├── alembic/
│ ├── versions/
│ ├── env.py
│ ├── script.py.mako
│ └── README
├── alembic.ini
└── main.py
El directorio alembic/ contiene toda la configuración y las migraciones, mientras que alembic.ini es el archivo de configuración principal.
Configuración básica
Necesitamos configurar Alembic para que se conecte a nuestra base de datos y reconozca nuestros modelos SQLAlchemy. Editamos el archivo alembic.ini:
# alembic.ini
[alembic]
script_location = alembic
prepend_sys_path = .
# Configuración de la base de datos
sqlalchemy.url = sqlite:///./app.db
[post_write_hooks]
[loggers]
keys = root,sqlalchemy,alembic
[handlers]
keys = console
[formatters]
keys = generic
La línea más importante es sqlalchemy.url, que debe apuntar a nuestra base de datos. Para proyectos en desarrollo, SQLite es una opción práctica.
Configuración del entorno de migraciones
El archivo alembic/env.py es donde configuramos cómo Alembic interactúa con nuestros modelos. Necesitamos modificarlo para que reconozca nuestros modelos SQLAlchemy:
# alembic/env.py
from logging.config import fileConfig
from sqlalchemy import engine_from_config, pool
from alembic import context
# Importamos nuestros modelos
from app.database import Base
from app.models import User, Post # Importar todos los modelos
# Configuración de Alembic
config = context.config
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# Metadatos de nuestros modelos
target_metadata = Base.metadata
def run_migrations_offline() -> None:
"""Ejecutar migraciones en modo offline."""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online() -> None:
"""Ejecutar migraciones en modo online."""
connectable = engine_from_config(
config.get_section(config.config_ini_section),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
Configuración para variables de entorno
En proyectos reales, es recomendable usar variables de entorno para la configuración de la base de datos. Podemos modificar alembic/env.py para leer estas variables:
# alembic/env.py (fragmento adicional)
import os
from dotenv import load_dotenv
# Cargar variables de entorno
load_dotenv()
# Configurar URL de base de datos desde variable de entorno
def get_url():
return os.getenv("DATABASE_URL", "sqlite:///./app.db")
def run_migrations_offline() -> None:
"""Ejecutar migraciones en modo offline."""
url = get_url()
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
Verificación de la configuración
Para verificar que Alembic está correctamente configurado, podemos ejecutar:
alembic current
Si la configuración es correcta, este comando nos mostrará la revisión actual de nuestra base de datos. En un proyecto nuevo, probablemente no mostrará ninguna revisión, lo cual es normal.
También podemos verificar que Alembic puede conectarse a la base de datos ejecutando:
alembic check
Este comando válida que la configuración sea correcta y que no haya inconsistencias entre nuestros modelos y el estado actual de la base de datos.
Con esta configuración básica, Alembic está listo para gestionar las migraciones de nuestra base de datos. El siguiente paso será crear y aplicar nuestras primeras migraciones para mantener sincronizada la estructura de datos con nuestros modelos SQLAlchemy.
Crear y aplicar migraciones básicas
Una vez configurado Alembic, podemos comenzar a crear migraciones para gestionar los cambios en nuestra base de datos. Las migraciones son scripts que describen cómo transformar la estructura de la base de datos de un estado a otro, permitiendo aplicar cambios de forma controlada y reversible.
Crear la primera migración
Para generar una migración inicial que incluya todos nuestros modelos existentes, utilizamos el comando revisión:
alembic revision --autogenerate -m "Crear tablas iniciales"
El parámetro --autogenerate hace que Alembic compare automáticamente nuestros modelos SQLAlchemy con el estado actual de la base de datos y genere el código necesario para sincronizarlos. El parámetro -m nos permite agregar un mensaje descriptivo.
Este comando crea un nuevo archivo en el directorio alembic/versions/ con un nombre similar a:
001_crear_tablas_iniciales_a1b2c3d4e5f6.py
Estructura de un archivo de migración
Examinemos el contenido de una migración generada automáticamente:
"""Crear tablas iniciales
Revision ID: a1b2c3d4e5f6
Revises:
Create Date: 2024-01-15 10:30:45.123456
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers
revision = 'a1b2c3d4e5f6'
down_revision = None
branch_labels = None
depends_on = None
def upgrade() -> None:
"""Aplicar cambios a la base de datos."""
# Crear tabla users
op.create_table('users',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('email', sa.String(length=255), nullable=False),
sa.Column('name', sa.String(length=100), nullable=False),
sa.Column('created_at', sa.DateTime(), nullable=True),
sa.PrimaryKeyConstraint('id')
)
op.create_index(op.f('ix_users_email'), 'users', ['email'], unique=True)
# Crear tabla posts
op.create_table('posts',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('title', sa.String(length=200), nullable=False),
sa.Column('content', sa.Text(), nullable=True),
sa.Column('user_id', sa.Integer(), nullable=False),
sa.Column('created_at', sa.DateTime(), nullable=True),
sa.ForeignKeyConstraint(['user_id'], ['users.id'], ),
sa.PrimaryKeyConstraint('id')
)
def downgrade() -> None:
"""Revertir cambios de la base de datos."""
op.drop_table('posts')
op.drop_index(op.f('ix_users_email'), table_name='users')
op.drop_table('users')
La función upgrade() contiene las operaciones para aplicar los cambios, mientras que downgrade() define cómo revertirlos.
Aplicar migraciones
Para aplicar la migración a nuestra base de datos, ejecutamos:
alembic upgrade head
El término head indica que queremos aplicar todas las migraciones hasta la más reciente. Alembic mostrará información sobre las operaciones realizadas:
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> a1b2c3d4e5f6, Crear tablas iniciales
Crear migraciones para cambios en modelos
Supongamos que necesitamos agregar una nueva columna is_active a nuestro modelo User:
# app/models.py
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
email = Column(String(255), unique=True, index=True, nullable=False)
name = Column(String(100), nullable=False)
is_active = Column(Boolean, default=True) # Nueva columna
created_at = Column(DateTime, default=lambda: datetime.now(timezone.utc))
Generamos una nueva migración para este cambio:
alembic revision --autogenerate -m "Agregar columna is_active a users"
Alembic detectará automáticamente el cambio y generará una migración similar a:
def upgrade() -> None:
"""Aplicar cambios a la base de datos."""
op.add_column('users', sa.Column('is_active', sa.Boolean(), nullable=True))
def downgrade() -> None:
"""Revertir cambios de la base de datos."""
op.drop_column('users', 'is_active')
Verificar el estado de las migraciones
Antes de aplicar cambios, podemos verificar qué migraciones están pendientes de aplicar:
alembic current
Este comando muestra la revisión actual de la base de datos. Para ver el historial completo de migraciones:
alembic history
La salida mostrará todas las migraciones disponibles:
a1b2c3d4e5f6 -> b2c3d4e5f6g7 (head), Agregar columna is_active a users
<base> -> a1b2c3d4e5f6, Crear tablas iniciales
Aplicar migraciones específicas
Podemos aplicar migraciones hasta una revisión específica en lugar de aplicar todas:
alembic upgrade a1b2c3d4e5f6
O aplicar solo la siguiente migración pendiente:
alembic upgrade +1
Migraciones manuales
Aunque --autogenerate es muy útil, a veces necesitamos crear migraciones manualmente para cambios que Alembic no puede detectar automáticamente:
alembic revision -m "Insertar datos iniciales"
Esto crea una migración vacía que podemos editar:
def upgrade() -> None:
"""Insertar datos iniciales."""
# Crear conexión para ejecutar SQL personalizado
connection = op.get_bind()
# Insertar usuario administrador
connection.execute(
"INSERT INTO users (email, name, is_active) VALUES (?, ?, ?)",
("admin@example.com", "Administrador", True)
)
def downgrade() -> None:
"""Eliminar datos iniciales."""
connection = op.get_bind()
connection.execute(
"DELETE FROM users WHERE email = ?",
("admin@example.com",)
)
Buenas prácticas para migraciones
Al trabajar con migraciones, es importante seguir algunas recomendaciones básicas:
- Revisar siempre el contenido de las migraciones generadas automáticamente antes de aplicarlas
- Usar mensajes descriptivos que expliquen claramente qué cambios introduce cada migración
- Probar las migraciones en un entorno de desarrollo antes de aplicarlas en producción
- No modificar migraciones que ya han sido aplicadas en otros entornos
Con estas operaciones básicas, podemos gestionar eficazmente los cambios en la estructura de nuestra base de datos, manteniendo la consistencia entre diferentes entornos y facilitando el trabajo colaborativo en equipo.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en FastAPI
Documentación oficial de FastAPI
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, FastAPI es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de FastAPI
Explora más contenido relacionado con FastAPI y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la importancia y función de Alembic para gestionar migraciones en bases de datos. Aprender a instalar y configurar Alembic en un proyecto FastAPI con SQLAlchemy. Saber cómo inicializar Alembic y adaptar su configuración para conectar con la base de datos y modelos. Crear, aplicar y revertir migraciones automáticas y manuales para mantener sincronizada la estructura de la base de datos. Conocer buenas prácticas para gestionar migraciones de forma segura y eficiente en entornos de desarrollo y producción.