Declaración y definición de estructuras
Las estructuras permiten agrupar múltiples variables de distintos tipos bajo un mismo identificador, fomentando un diseño más organizado del código. Con la palabra clave struct, se pueden crear tipos compuestos que representan entidades lógicas como un registro, un vector de atributos o cualquier objeto con propiedades heterogéneas.
Para definir una estructura, se utiliza la siguiente sintaxis, donde primero se especifica la palabra clave struct, seguida de un nombre opcional y, dentro de llaves, la lista de miembros con sus tipos y nombres:
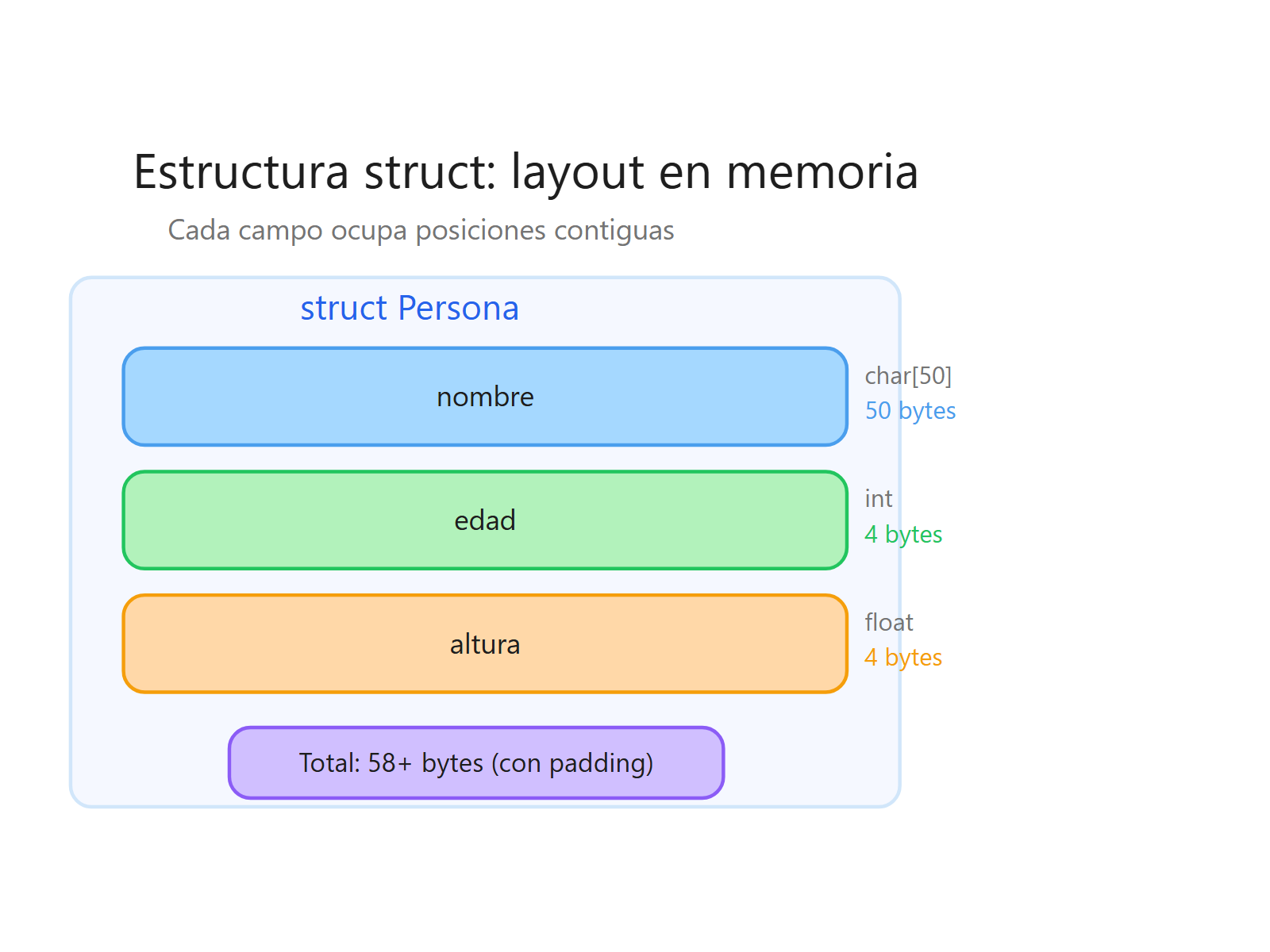
struct Persona {
char nombre[50];
int edad;
float altura;
};
También es posible omitir el nombre de la estructura, aunque en desarrollos complejos se recomienda mantenerlo para reutilizar ese tipo en distintos puntos del código.
Separar la declaración de la definición resulta útil en proyectos grandes: la declaración se limita a exponer la existencia del tipo (por ejemplo, struct Persona; sin miembros) para referencias adelantadas, mientras que la definición cubre detalladamente cada campo que lo compone. Esto ayuda a mantener un orden claro en los archivos de cabecera y en las implementaciones.
En entornos donde se busca modularidad, se suele colocar la definición de la estructura en un único archivo de cabecera para que el resto de módulos puedan incluirla sin redundancias. Así, se evitan copias innecesarias del mismo tipo y se facilita la gestión de cambios posteriores en los miembros de la estructura.
Acceso a miembros de la estructura
Para acceder a los campos de una estructura cuando se trabaja con una variable directa, se emplea el operador .. Este operador indica que se está usando el valor de la variable, sin necesidad de ningún tipo de desreferencia. Por ejemplo, si se dispone de un objeto persona1 y se desea asignar la edad y altura, basta con realizar:
persona1.edad = 30;
persona1.altura = 1.75f;
En este caso, el operador . proporciona un acceso directo a los miembros internos, ya que la variable persona1 no es un puntero.
La situación cambia cuando se manipula un puntero a una estructura. En ese contexto, el operador -> facilita la desreferencia interna hacia el miembro correspondiente. La flecha combina el acceso indirecto con la selección del campo, lo que evita escribir (*puntero).miembro. Si se tiene struct Persona *pPersona = &persona1;, se podría modificar un atributo así:
pPersona->edad = 35;
pPersona->altura = 1.80f;
De este modo, -> realiza internamente la desreferencia necesaria y permite tratar a cada miembro como si fuera parte de la estructura apuntada.
Cuando se accede a campos dentro de un programa complejo, es recomendable mantener una consistencia de estilo para que sea más legible el uso de . y ->. Desplegar cada asignación o lectura en una línea separada ayuda a identificar posibles errores y a comprender con claridad el flujo de acceso a los datos. Lista de sugerencias:
- Mantener una nomenclatura clara en las variables y punteros para diferenciar fácilmente cada tipo de acceso.
- Utilizar
->únicamente si se trabaja con un puntero o referencia hacia la estructura, evitando confusiones en el código. - Acompañar cada acceso a miembros con comentarios breves pero significativos, sobre todo cuando se modifiquen varios campos consecutivos.
Estructuras anidadas
Las estructuras anidadas permiten representar relaciones internas más específicas al encapsular una estructura dentro de otra. Este enfoque es útil cuando se requiere organizar datos de forma jerárquica o describir atributos que pertenecen a distintas categorías sin recurrir a múltiples tipos externos.
Un ejemplo ilustrativo consiste en agrupar la información de una dirección dentro de la estructura de una persona. Así, se pueden definir los campos de la siguiente manera:
struct Direccion {
char calle[50];
int numero;
};
struct Persona {
char nombre[50];
struct Direccion direccion;
};
En el caso anterior, se accede a cada subcampo utilizando el operador . según corresponda. Si existe una variable persona1 de tipo struct Persona, para asignar el nombre de la calle se puede emplear:
strcpy(persona1.direccion.calle, "Avenida Central");
persona1.direccion.numero = 123;
Cada miembro de la subestructura queda así integrado de manera coherente bajo el ámbito de Persona.
Al diseñar estructuras anidadas, conviene mantener una distribución coherente de los campos, de modo que las responsabilidades de cada parte estén bien delimitadas. Algunos consejos valiosos incluyen:
- Diseñar la lógica de cada estructura en torno a un objetivo claro.
- Agrupar los campos relacionados en subestructuras para facilitar la lectura y la reutilización de datos.
- Revisar la distribución de tamaños y tipos para asegurar un control óptimo de la memoria.
Arreglos y punteros a estructuras
Cuando se utilizan arreglos de estructuras, todos los elementos comparten el mismo tipo de struct, pero cada posición mantiene valores independientes en sus campos. Por ejemplo, se puede declarar un array local de struct Persona para gestionar un grupo de hasta 100 registros, cada uno con sus propias características. Una aproximación común es recorrer el array con un bucle for, asignar valores a cada miembro y, si es necesario, aplicar operaciones de búsqueda o filtrado sobre cada estructura.
Un arreglo de estructuras también puede combinarse con punteros a estructuras para acceder a regiones concretas del array o para pasarlo como argumento a funciones. Por norma general, se podría utilizar un puntero para apuntar al primer elemento del array y así iterar sobre él sin necesidad de índices. Esto permite escribir expresiones más compactas usando el operador ->. Un esquema típico de acceso es:
#include <stdio.h>
struct Persona
{
int edad;
float altura;
};
int main(void)
{
struct Persona grupo[5];
struct Persona *p = grupo; // p apunta al inicio del array
for (int i = 0; i < 5; i++)
{
p->edad = 20 + i;
p->altura = 1.70f + 0.01f * i;
p++;
}
for (int i = 0; i < 5; i++)
{
printf("Persona %d: Edad: %d, Altura: %f\n", i, grupo[i].edad, grupo[i].altura);
}
return 0;
}
En este bloque, el puntero avanza a través de cada elemento y desreferencia los campos con el operador ->, sin necesidad de utilizar grupo[i].edad o grupo[i].altura.
Cuando se pasan arreglos de estructuras a funciones, es habitual usar la forma funcion(struct Persona *arr, int tam), de manera que dentro de la función se opere con el puntero a la primera posición y un entero que indica el tamaño del array. Esta estrategia resulta útil para generar rutinas de inicialización, clasificación o búsqueda de datos sin duplicar la memoria. Además, al manejar punteros, se tiene la flexibilidad de aplicar la misma función a segmentos concretos del array, restringiendo el ámbito según sea necesario.
En escenarios donde se requiere memoria dinámica, se puede reservar espacio para un conjunto de estructuras con malloc() y tratar la dirección de retorno como un puntero al primer elemento del array. Por ejemplo:
#include <stdio.h>
#include <stdlib.h>
struct Persona
{
int edad;
float altura;
};
int main(void)
{
struct Persona *conjunto = malloc(10 * sizeof(struct Persona));
if (conjunto != NULL)
{
// Inicializar cada estructura...
// Uso de conjunto[i] o (conjunto + i)->campo
for (int i = 0; i < 10; i++)
{
conjunto[i].edad = i;
(conjunto + i)->altura = 1.0f + i;
}
}
for (int i = 0; i < 10; i++)
{
printf("Edad: %d, Altura: %f\n", (conjunto + i)->edad, conjunto[i].altura);
}
free(conjunto);
return 0;
}
Con este patrón, la gestión de la memoria asignada queda bajo control del desarrollador, resultando práctico para trabajos en los que el tamaño del conjunto de datos no se conoce en tiempo de compilación.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, C es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de C
Explora más contenido relacionado con C y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Identificar la utilidad de las estructuras para organizar datos heterogéneos. 2. Diferenciar entre declaración y definición de estructuras. 3. Usar los operadores
.y->para acceder a los miembros de las estructuras. 4. Implementar estructuras anidadas para representar jerarquías de datos complejas. 5. Gestionar arreglos y punteros a estructuras, optimizando el uso de memoria.